Introduction
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What is Palmetto?
Objectives
Palmetto is a supercomputing cluster: a set of powerful computers that are connected to each other. It is built and maintained by Clemson University, and is located off campus, close to Anderson SC, in a dedicated building which is powered by a dedicated power plant.

The Palmetto cluster is maintained by two teams: a team of system administrators, who work directly at the cluster, and monitors its hardware and operating system, and a team of research facilitators, who work with the Palmetto users. The two teams work very closely together. As research facilitators, we provide training workshops, online help and support, and in-person office hours (which are currently on Zoom).

We maintain a very extensive website which hosts plenty of information for Palmetto users. We have more than 2000 people using Palmetto; they come from a variety of departments: Computer Science, Chemistry, Biology, Public Health, Engineering, Mathematics, Psychology, Forestry, etc. In addition to Clemson, we have researchers from many other universities using Palmetto.
Key Points
Palmetto is a very powerful high-performance computing cluster
Accessing the Palmetto Cluster
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How can I access the Palmetto cluster from my local machine?
Objectives
SSH client, Terminal, MobaXTerm
Pametto is accessed using the SSH (“Secure shell”) protocol. Palmetto runs the SSH server; on your local machine, you will need to run SSH client which connects to a server using a command-line terminal. The commands that are entered on the terminal are processed by the server on Palmetto.
To start the SSH client on a Mac, you can open the Terminal Application (which is usually located in Applications → Utilities) and run the following:
ssh login.palmetto.clemson.edu
For Windows, first you need to download and install MobaXterm Home Edition.
It is important that you unzip the downloaded installer prior to installation. The zipped installer file contains an additional data file besides the installer executable. This data file is not accessible if the installer executable is called from inside the zipped file (something Windows allows you to do).
After MobaXterm starts, click the Session button.
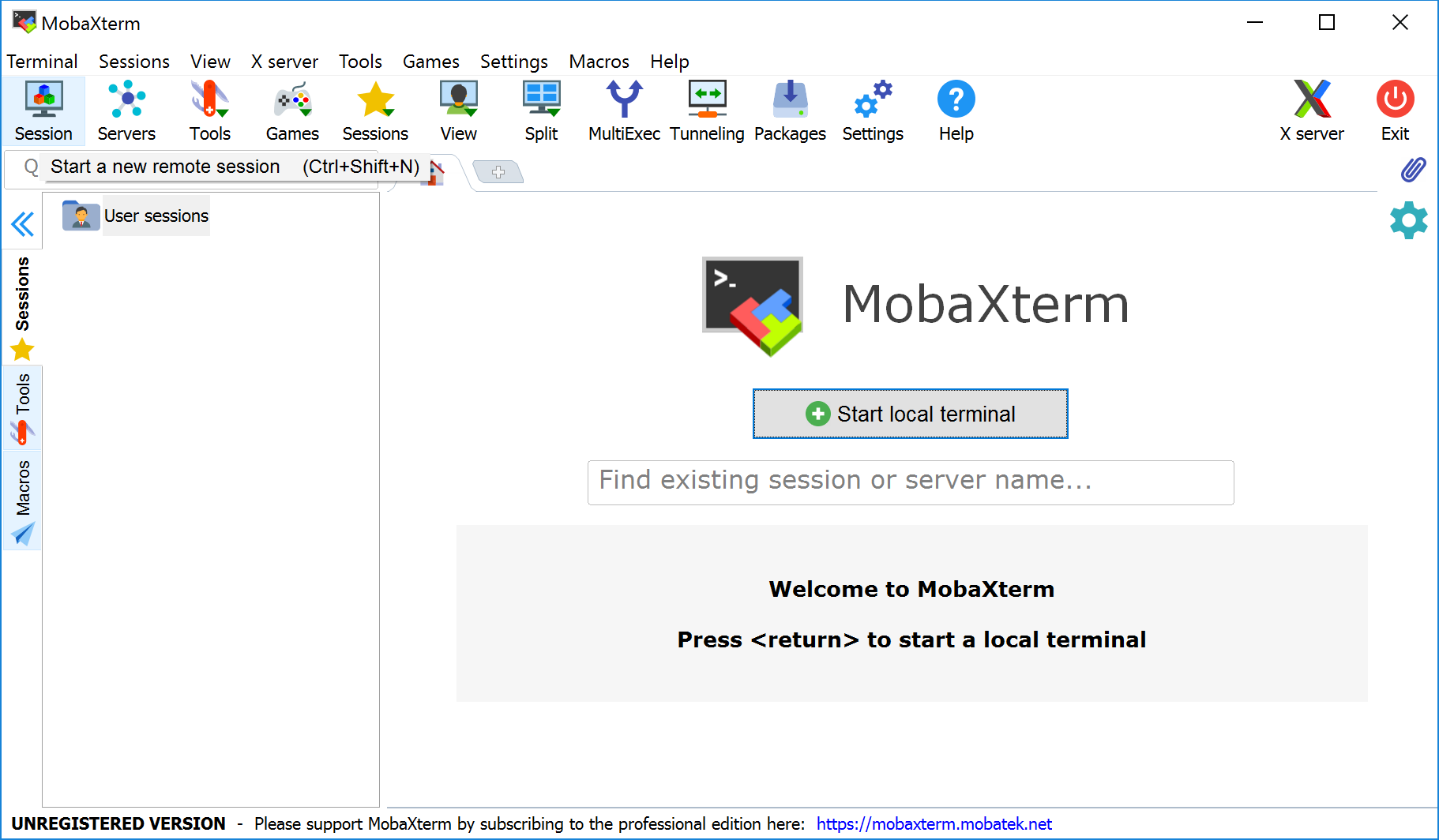
Select SSH session and use the following parameters (whichever required), then click OK:
- Remote host:
login.palmetto.clemson.edu - SSH-browser type: Enhanced SCP
- Port: 22
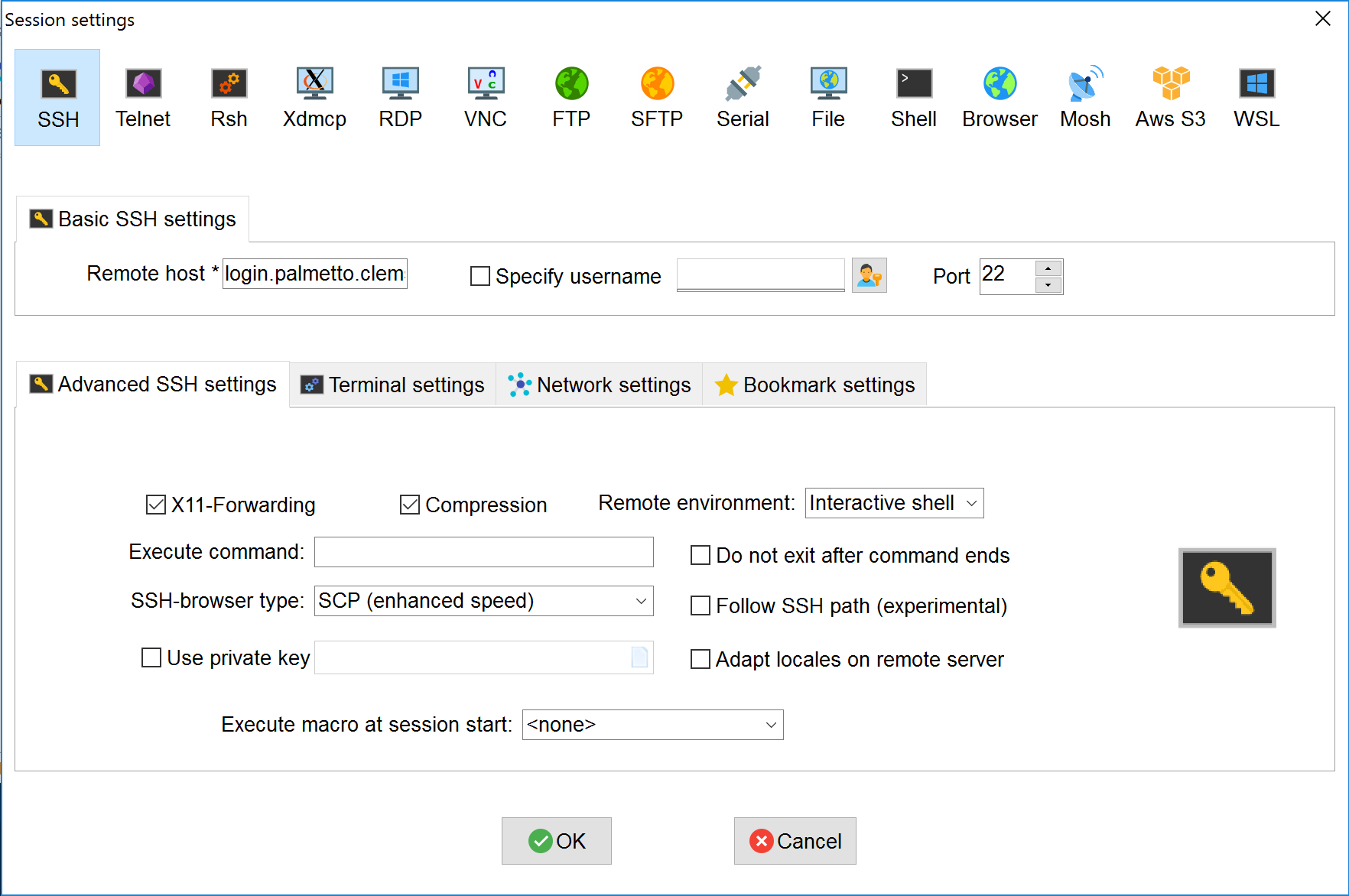
At this stage, for both Mac and Windows, you will be asked to enter your username and password, then DUO option.
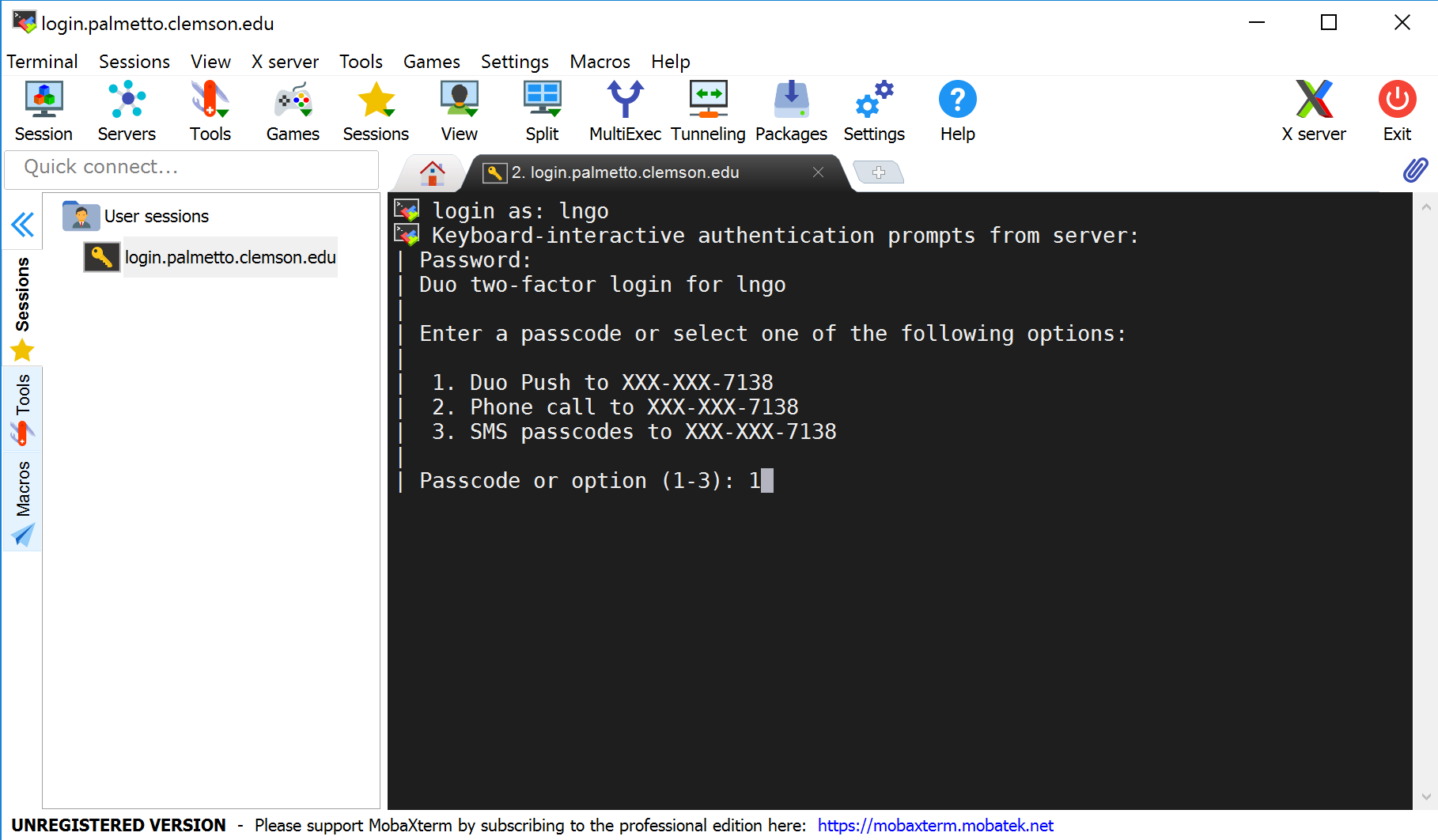
When logged in, you are presented with a welcome message and the following “prompt”:
[username@login001 ~]$
The prompt in a bash shell usually
contains a ($) sign,
and shows that the shell is waiting for input.
The prompt may also contain other information:
this prompt tells you your username and which node
you are connected to -
login001 is the “login” node.
It also tells you your current directory,
i.e., ~, which, as you will learn shortly,
is short for your home directory.
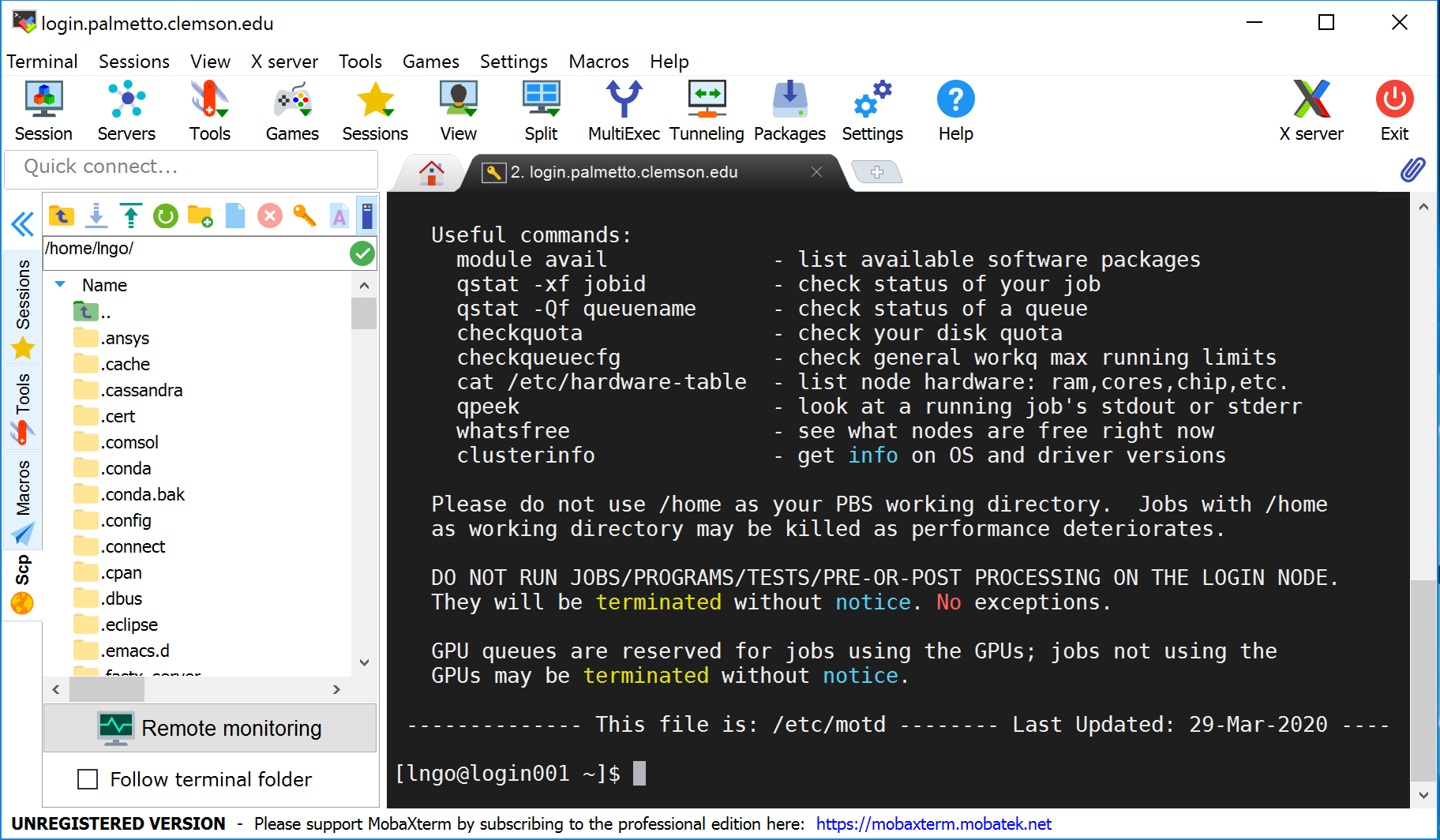
In the figure below, MobaXterm also gives you a GUI browser of your home directory on Palmetto. For Mac OS and Linux terminal, you will only have the command line interface to the right.
Key Points
Palmetto can be accessed by an SSh (secure shell) client
Windows user can use
MobaXTermapplicationMac users can use the
Terminalapplication
The structure of the Palmetto Cluster
Overview
Teaching: 15 min
Exercises: 0 minQuestions
What is the structure of the Palmetto Cluster?
Objectives
compute and login nodes, hardware table,
whatsfree
The computers that make up the Palmetto cluster are called nodes. Most of the nodes on Palmetto are compute nodes,
that can perform fast calculations on large amounts of data. There is also a special node called the login node; it runs the server,
which works like the interface
between the cluster
and the outside world. The people with Palmetto accounts can log into the server by running a client (such as ssh) on their local machines.
Our client program passes our login credentials to this server, and if we are allowed to log in, the server runs a shell for us.
Any commands that we enter into this shell are executed not by our own machines, but by the login node.
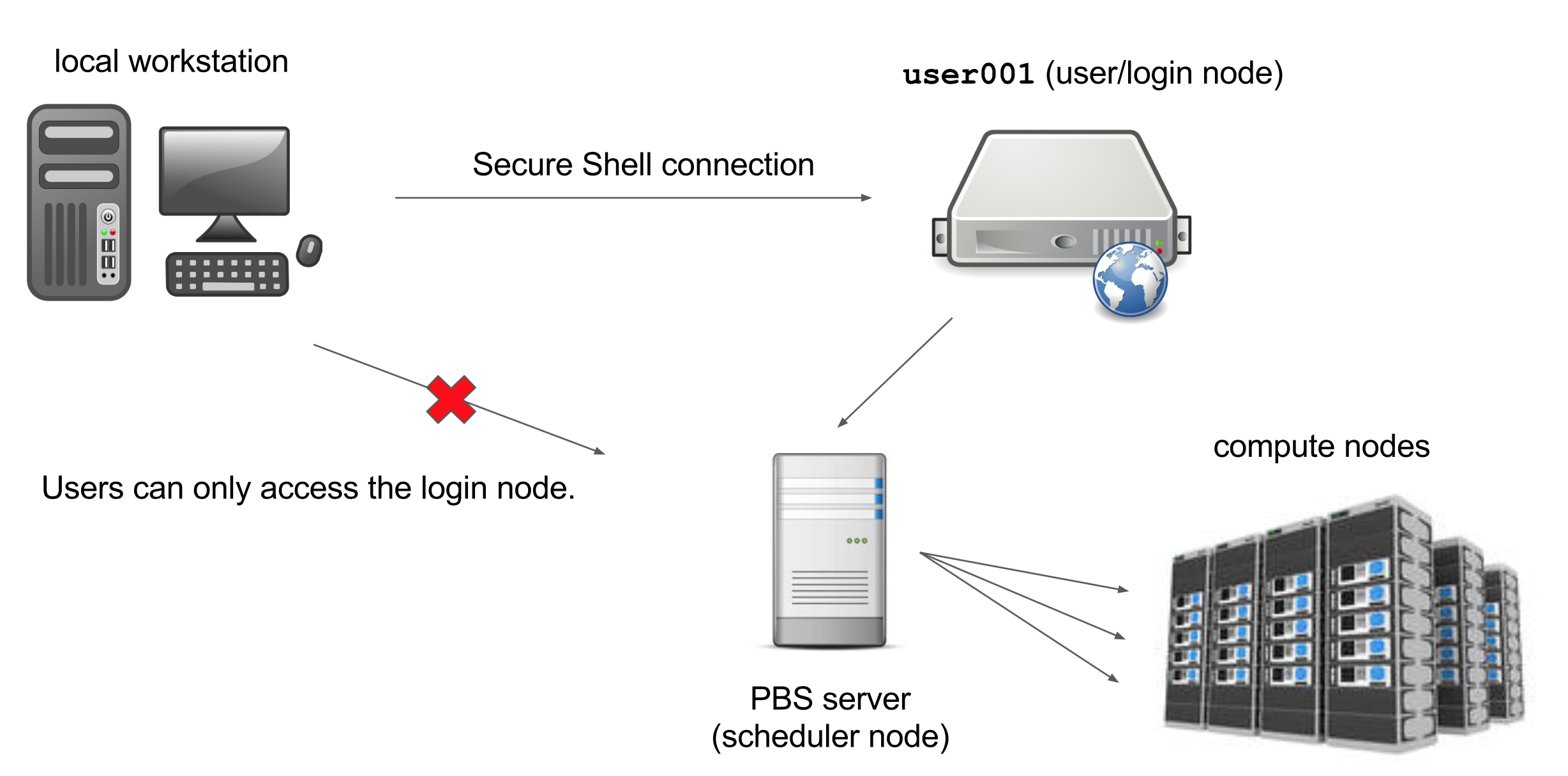
Another special node is the scheduler; Palmetto users can get from the login node to the compute nodes by submitting a request to the scheduler, and the scheduler will assign them to the most appropriate compute node. Palmetto also has a few so-called “service” nodes, which serve special purposes like transferring code and data to and from the cluster, and hosting web applications.
The Skylight nodes are integrated into Palmetto. To see the specifications of the Skylight compute nodes, let’s type
cat /etc/hardware-skylight
This will print out a text file with the hardware info. Please make sure you type exactly as shown; Linux is case-sensitive, space-sensitive, and typo-sensitive. The output will look something like this:
--------------------------------------------------------
SKYLIGHT HARDWARE TABLE Last updated: May 11 2021
--------------------------------------------------------
QUEUE COUNT MAKE MODEL CHIP(1) CORES RAM /local_scratch GPUs(2)
skystd 22 ACT S2600TPFR Intel Xeon E5-2640v4 20 125 GB 800 GB 0
skystd 24 Dell R640 Intel Xeon 6230R 52 754 GB 3.4 TB 0
skylm 3 ACT 2USERVER Intel Xeon E5-2680v4 28 503 GB 800 GB 0
skylm 5 Dell R640 Intel Xeon 6230R 52 1500 GB 3.4 TB 0
skygpu 6 ACT ESC4000G3 Intel Xeon E5-2640v4 20 62 GB 800 GB 4 x NVIDIA GTX1080
skygpu 2 ACT 2USERVER Intel Xeon E5-2640v4 20 125 GB 800 GB 1 x NVIDIA P100
skygpu 6 Dell DSS840 Intel Xeon 6230R 52 380 GB 3.4 TB 8 x NVIDIA RTX6000
The Skylight nodes are grouped into three queues: skystd (Skylight standard), slylm (Skylight large memory), and skygpu (Skylight GPU). The number of nodes accessible through each queue is respectively, 46, 8, and 14. The first queue is the “standard” nodes which are good for most applications. Each node has either 20 or 52 cores, or CPUs, or processors. This means that you can run 20 (or 52) processes in parallel. If the software can organize its operations into 20 (or 52) parallel processes, it will run considerably faster (and a lot fo software is really good at this, Matlab and LAMMPS being just two examples). The standard nodes have 125 (or 754) Gb of RAM. If your software needs more RAM than that, you should use the nodes in the large memory queue; they have up to 1.5 Tb of RAM. Finally, some software really benefits from using GPU (graphical processing unit, which is basically a video card). In addition to running video, GPUs can be utilized for really fast and efficient computations. Six nodes in the GPU queue have GTX-1080 cards (four per node), two nodes have P100 cards (one per node), and six nodes have RTX-6000 cards; the P100 card is the most powerful.
To see which nodes are available at the moment, you can type
whatsfree
It will produce a lot of output, but the relevant part is the Skylight nodes:
SKYLIGHT CLUSTER (Mercury Consortium)
PHASE 25a TOTAL = 22 FREE = 0 OFFLINE = 1 TYPE = ACT Intel Xeon E5-2640v4, 20 cores, 125GB, 1ge
PHASE 25b TOTAL = 3 FREE = 0 OFFLINE = 0 TYPE = ACT Intel Xeon E5-2680v4, 28 cores, 503GB, 1ge
PHASE 25c TOTAL = 6 FREE = 0 OFFLINE = 0 TYPE = ACT Intel Xeon E5-2640v4, 20 cores, 62GB, 1ge, GTX1080
PHASE 25d TOTAL = 2 FREE = 0 OFFLINE = 0 TYPE = ACT Intel Xeon E5-2640v4, 20 cores, 125GB, 1ge, P100
PHASE 26a TOTAL = 24 FREE = 0 OFFLINE = 0 TYPE = Dell R640 Intel Xeon 6230R, 52 cores, 754GB, 25ge
PHASE 26b TOTAL = 5 FREE = 0 OFFLINE = 0 TYPE = Dell R640 Intel Xeon 6230R, 52 cores, 1500GB, 25ge
PHASE 26c TOTAL = 6 FREE = 0 OFFLINE = 0 TYPE = Dell DSS840 Intel Xeon 6230R, 52 cores, 380GB, 25ge, RTX6000
Phases 25 and 26 are the Skylight nodes. Phase 25 is the initial purchase, and phase 26 is the more recent one. Phases 25a and 26a are accessed through the skystd queue; phases 25b and 26b are accessed through skylm (“large memory”) queue; and finally phases 25c, 25d, and 26c are accessed through the skygpu queue.
This table shows the amount of completely free nodes per each phase; a node which has, for example, 8 cores, but only 4 of them are used, would not be counted as “free”. So this table is a conservative estimate. It is a good idea to run whatsfree when you log into Palmetto, to get a picture of how busy the cluster is. This picture can change pretty drastically depending on the time of the day and the day of the week.
If a compute node is not 100% busy, you can still get on it. For example, the compute nodes in phase 26c have 52 cores, 280 GB of RAM, and 8 GPUs. If you are fine with using a subset of these resources, the freeres script can be very convenient: it tells you which nodes are partially available. Let’s run it for phase 26c:
freeres phase26c
group file = /software/caci/cluster/phase26c
CPU | GPU | Memory (GB) |
Node Avail Used Free | Avail Used Free | Avail Used Free | State
---------------------------------------------------------------------------
skygpur1 52 51 1 8 3 5 376 186 190 free
skygpur2 52 51 1 8 3 5 376 186 190 free
skygpur3 52 51 1 8 3 5 376 186 190 free
skygpur4 52 51 1 8 3 5 376 186 190 free
skygpur5 52 34 18 8 2 6 376 124 252 free
skygpur6 52 51 1 8 3 5 376 224 152 free
checked 6 nodes in 0.40 Seconds
So if you ask for no more than 18 CPUs, 252 GB of RAM, and 6 GPUs, you will still be able to get on a Phase 26c compute node without having to wait in line.
Key Points
Palmetto contains more than 2000 interconnected compute nodes
a phase is a group of compute nodes that have the same architecture (CPUs, RAM, GPUs)
a specialized login node runs the SSH server
Storage on Palmetto
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How and where can I store my files?
Objectives
home directory, scratch space
Every Palmetto user gets 100 Gb of storage space; this storage is backed up at the end of every day, and the backup is kept for 42 days. So if you accidentally delete a file that was created more than a day ago, we might be able to restore it. This storage is called home directory.
To see how much space you have left in your home directory, please type:
checkquota
Since most of you are new users of Palmetto, you should be using very little storage at the moment.
When you log into Palmetto, you end up in your home directory. To see which directory you are in, type
pwd
…which stands for “print working directory”. It should give you something like
/home/<your Palmetto username>
100 Gb might be enough for some, but for people dealing with extensive amounts of data that would not be enough. We also offer the access to scratch space, which is about 2+ Petabytes in total. Scratch space is not backed up; files that haven’t been used for more than a month are automatically deleted (and cannot be restored). We strongly encourage people to use scratch space, but please be aware of its temporary nature. When you get anything that is worth keeping, please back it up, either in your home directory, or on your local machine.
To go to a scratch directory, or to any directory on Palmetto, use the cd (“change directory”) command:
cd /scratch1/<your Palmetto username>
To go to your home directory, you can do
cd /home/<your Palmetto username>
There is also a shortcut; to go to your home directory, you can simply type
cd
NOTE: please don’t use /tmp for temporary storage! Use /scratch1 or $TMPDIR.
Key Points
users get 100 Gb of backed-up storage in their home directories
they also have access to more than 2 Pb of scratch storage
scratch storage is not backed up, and files left unused for 1 month are deleted
Running an interactive job on Palmetto
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How do I request and interact with a compute node?
Objectives
qsub,pbsnodes, modules
Now, we arrive at the most important part of today’s workshop: getting on the compute nodes. Compute nodes are the real power of Palmetto. Let’s see which of the compute nodes are available at the moment:
whatsfree
We can see that the cluster is quite busy, but there is a fair amount of compute nodes that are available for us. Now, let’s request one compute node in the skystd queue. Please type the following (or paste from the website into your SSH terminal):
qsub -I -q skystd
The qsub command will send a request to the scheduler. Once the request is granted, you will see something like that:
qsub (Warning): Interactive jobs will be treated as not rerunnable
qsub: waiting for job 631266.pbs02 to start
qsub: job 631266.pbs02 ready
[gyourga@skystd01 ~]$
Importantly, you will see the prompt change. Perviously, the prompt was
exit
Now, you will see the prompt changing back to login001.
The qsub command that we have entered used the default parameters: one CPU, 2 Gb of RAM, and 24 hours of walltime (walltime is the amount of time you are requestng for the compute node; once this time is over, you are kicked out from the compute node). This request is very modest and not particularly practical. Let’s do a more relevant request: four CPUs, 10 Gb of RAM, and two hours of walltime:
qsub -I -q skystd -l select=1:ncpus=4:mem=10gb,walltime=2:00:00
It is very important not to make typos, use spaces and upper/lowercases exactly as shown, and use the proper punctuation (note the : between ncpus and mem, and the , before walltime). If you make a mistake, nothing wrong will happen, but the scheduler won’t understand your request.
Now, let’s carefully go through the request:
qsubmeans that we are asking the scheduler to grant us access to a compute node;-Imeans it’s an interactive job (we’ll talk about it in a bit);-qspecifies the Skylight queue;-lis the list of resource requirements we are asking for;select=1means we are asking for one compute node;ncpus=4means that we only need four CPUs on the node (since all Palmetto compute nodes have at least 8 CPUs, we might share the compute node with other users, but it’s OK because users who use the same node do not interfere with each other);mem=10gbmeans that we are asking for 10 Gb of RAM (you shouldn’t ask for less than 8 Gb); again, memory is specific to the user, and not shared between different users who use the same node);- finally,
walltime=2:00:00means that we are asking to use the node for 2 hours; after two hours we will be logged off the compute node if we haven’t already disconnected.
This is actually a quite modest request as well, and the scheduler should grant it right away. Sometimes, when we are asking for much substantial amount of resources (for example, 10 nodes with 20 cores and 370 Gb of RAM), the scheduler cannot satisfy our request, and will put us into the queue so we will have to wait until the node becomes available. If you don’t want to wait, you can press Ctrl+C.
Once the request is granted, you will see something like that:
qsub (Warning): Interactive jobs will be treated as not rerunnable
qsub: waiting for job 1649928.pbs02 to start
qsub: job 1649928.pbs02 ready
(base) [gyourga@skystd01 ~]$
Please note two important things. First, our prompt changes from login001 no skystdXX, where XX is some four-digit number. This is the number of the node that we got (in our case, 01). The second one is the job ID, which is 1649928. We can see the information about the compute node by using the pbsnodes command:
pbsnodes skystd01
Here is the information about the node that I was assigned to (skystd01):
(skystd01
Mom = skystd01.palmetto.clemson.edu
ntype = PBS
state = job-busy
pcpus = 20
Priority = 25
jobs = 1636248.pbs02/0, 1636248.pbs02/1, 1636248.pbs02/2, 1636248.pbs02/3, 1636248.pbs02/4, 1636248.pbs02/5, 1636248.pbs02/6, 1636248.pbs02/7, 1636248.pbs02/8, 1636248.pbs02/9, 1636248.pbs02/10, 1636248.pbs02/11, 1636248.pbs02/12, 1636248.pbs02/13, 1636248.pbs02/14, 1636248.pbs02/15, 1649928.pbs02/16, 1649928.pbs02/17, 1649928.pbs02/18, 1649928.pbs02/19
resources_available.arch = linux
resources_available.chip_manufacturer = intel
resources_available.chip_model = xeon
resources_available.chip_type = e5-2640v4
resources_available.host = skystd01
resources_available.hpmem = 0b
resources_available.interconnect = 1g, 56g, fdr
resources_available.make = act
resources_available.manufacturer = act
resources_available.mem = 131659892kb
resources_available.model = act
resources_available.ncpus = 20
resources_available.ngpus = 0
resources_available.node_make = act
resources_available.node_manufacturer = act
resources_available.node_model = act
resources_available.nphis = 0
resources_available.phase = 25a
resources_available.qcat = skylight_qcat, skystd_qcat, c2_workq_qcat
resources_available.ssd = False
resources_available.vmem = 129470mb
resources_available.vnode = skystd01
resources_assigned.accelerator_memory = 0kb
resources_assigned.hbmem = 0kb
resources_assigned.mem = 73400320kb
resources_assigned.naccelerators = 0
resources_assigned.ncpus = 20
resources_assigned.ngpus = 0
resources_assigned.nphis = 0
resources_assigned.vmem = 0kb
resv_enable = True
sharing = default_shared
last_state_change_time = Fri Feb 12 14:07:24 2021
last_used_time = Fri Feb 12 14:07:24 2021
You can see that the node has 20 CPUs, no GPUs, and at the moment runs a bunch of jobs. One of these jobs is mine (1649928). When I submitted qsub request, the scheduler told me that my job ID is 1649928. The pbsnodes command gives us the list of jobs that are currently running on the compute node, and, happily, I see my job on that list. It appears four times, because I have requested four CPUs. Somebody else runs a job (1636248) which takes the remaining 16 CPUs.
To exit the compute node, type:
exit
This will bring you back to the login node. See how your prompt has changed to login001. It is important to notice that you have to be on a login node to request a compute node. One you are on the compute node, and you want to go to another compute node, you have to exit first.
For some jobs, you might want to get a GPU, or perhaps two GPUs. For such requests, the qsub command needs to specify the number of GPUs and the type of GPUs (which you can get from cat /etc/hardware-skylight); we will also have to use the skygpu queue. For example, let’s request a NVIDIA Tesla GTX-1080:
qsub -I -q skygpu -l select=1:ncpus=4:mem=10gb:ngpus=1:gpu_model=gtx1080,walltime=2:00:00
You might have to wait for a bit of the GTX-1080 nodes are busy. Once you get on the compute node, exit it to let other people a chance to get on it.
If you want a GPU but don’t care about the type of the GPU, you can request gpu_model=any.
It is possible to ask for several compute nodes at a time, for example select=4 will give you 4 compute nodes. Some programs, such as LAMMPS or NAMD, work a lot faster if you ask for several nodes. This is an advanced topic and we will not discuss it here, but you can find some examples on our website.
NOTE: please be considerate of others when you issue qsub. Remember that Palmetto is a shared resource. For example, maximum walltime is 10 days, but please don’t ask for 10 days of walltime if you only plan to run your program for two hours. The same goes for CPUs and memory: if you have a small program, don’t ask for 500 Gb of RAM.
It is very important to remember that you shouldn’t run computations on the login node, because the login node is shared between everyone who logs into Palmetto, so your computations will interfere with other people’s login processes. However, once you are on a compute node, you can run some computations, because each user gets their own CPUs and RAM so there is no interference. If you are on the compute node, exit it. Once you get on the login node, type this:
qsub -I -q skystd -l select=1:ncpus=4:mem=10gb,walltime=2:00:00
We have a lot of software installed on Palmetto, but most of it is organized into modules, which need to be loaded. To see which modules are available on Palmetto, please type
module avail
Hit SPACE several times to get to the end of the module list. This is a very long list, and you can see that there is a lot of software installed for you. If you want to see which versions of LAMMPS are installed, you can type
module avail lammps
---------------------------------------------------- /software/ModuleFiles/modules/linux-centos8-x86_64 -----------------------------------------------------
lammps/20190807-gcc/8.3.1-cuda10_2-mpi-openmp-user-omp lammps/20200505-gcc/8.3.1-cuda10_2-kokkos-mpi-nvidia_V-openmp-user-omp
lammps/20200505-gcc/8.3.1-cuda10_2-kokkos-mpi-nvidia_K-openmp-user-omp lammps/20200505-gcc/8.3.1-cuda10_2-mpi-nvidia_K-openmp-user-omp (D)
lammps/20200505-gcc/8.3.1-cuda10_2-kokkos-mpi-nvidia_P-openmp-user-omp
------------------------------------------------------------------- /software/AltModFiles -------------------------------------------------------------------
lammps/20200505-nvidia_V_kokkos
Where:
D: Default Module
Use "module spider" to find all possible modules and extensions.
Use "module keyword key1 key2 ..." to search for all possible modules matching any of the "keys".
Let’s say you want to use R. To load the module, you will need to specify its full name.To see which versions of R are available, type
module avail r
This will give you a list of all modules which have the letter “r” in them (module avail is not very sophisticated). Let’s see what happens when you load the R 4.0.2 module:
module load r/4.0.2-gcc/8.3.1
module list
Currently Loaded Modules:
1) tcl/8.6.8-gcc/8.3.1 2) openjdk/11.0.2-gcc/8.3.1 3) libxml2/2.9.10-gcc/8.3.1 4) libpng/1.6.37-gcc/8.3.1 5) r/4.0.2-gcc/8.3.1
R depends on other software to run, so we have configured the R module in a way that when you load it, it automatically loads other modules that it depends on.
To start command-line R, you can simply type
R
To quit R, type
quit()
Key Points
whatsfreeshows the current Palmetto usage
qsubsends a request for a compute node to the schedulersoftware available on Palmetto is organized into modules according to version
modules need to be loaded before use
Running a batch job
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How do I run my computations on a compute node on the background?
Objectives
PBS scripts,
qstat,checkqueuecfg,nano
Interactive jobs are great if you need to do something quick, or perhaps visualize some data. If you have some code which runs for seven hours, interactive jobs are not a great idea. Please keep in mind that an interactive job gets killed if you close the SSH connection. So for example, you connect to Palmetto from your laptop, start an interactive job, but then your laptop runs out of battery power and you can’t find your charger. SSH client quits, and your interactive job is killed.
If you have some truly serious, multi-hour computation project (and that’s what Palmetto is really good for), a better idea is to run it on the background. This is called a batch job. You submit it in a fashion which is conceptually similar to an interactive job, but then it runs on the compute node on the background until it’s over. If it needs to take two days, it takes two days. You can quit the SSH client or close your laptop, it won’t affect the batch job.
To submit a batch job, we usually create a separate file called a PBS script. This file asks the scheduler for specific resources, and then specifies the actions that will be done once we get on a compute node.
Let us go through an example. We will use batch mode to create a small random matrix with normally-distributed values. We will create two scripts: an R script which does the computation, and a PBS script which will execute the R script on a compute node in batch mode.
Palmetto has a simple text editor which is called nano. It doesn’t offer any fancy formatting, but it suffices for ceating and editing simple texts. Let’s go to our home directory and create the R script:
cd
nano randmatrix.r
This will open the nano text editor:
![]()
Inside the editor, type this:
M <- matrix(rnorm(16), nrow=4)
M
Instead of typing, you can copy the text from the Web browser and paste it into nano. Windows users can paste with Shift+Ins (or by right-clicking the mouse). Mac users can paste with Cmd+V. At the end, your screen should look like this:
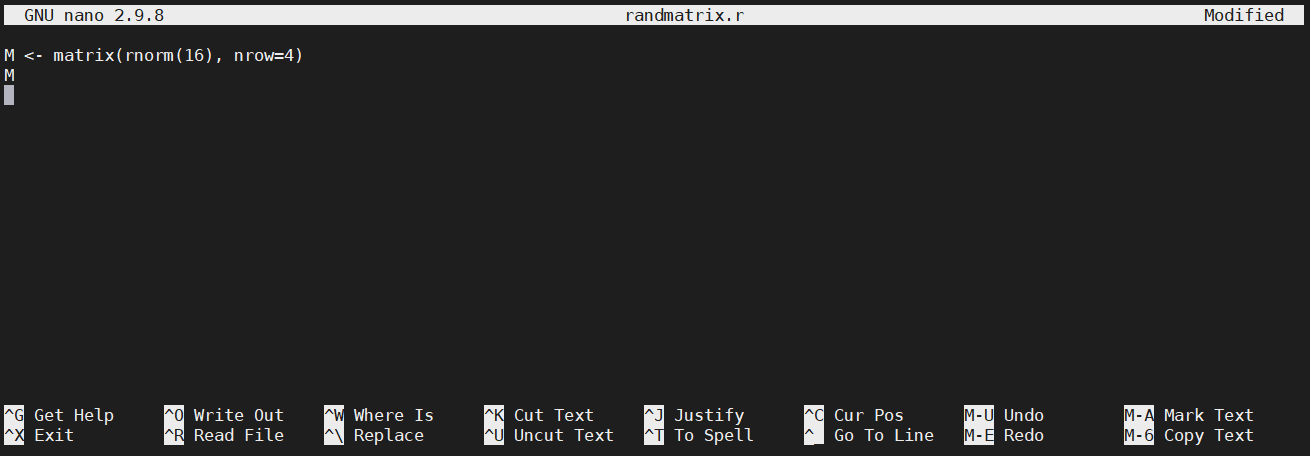
To save it, press Ctrl+O, and hit enter. To exit the editor, press Ctrl+X. To make sure the text is saved properly, print it on screen using the cat command:
cat randmatrix.r
Now, let’s create the PBS script:
nano randmatrix.sh
Inside the nano text editor, type this (or paste from the Web browser):
#!/bin/bash
#
#PBS -N random_matrix
#PBS -l select=1:ncpus=10:mem=10gb
#PBS -l walltime=0:20:00
#PBS -q skystd
#PBS -o random_matrix.txt
#PBS -j oe
cd $PBS_O_WORKDIR
module load r/4.0.2-gcc/8.3.1
Rscript randmatrix.r
Let’s go through the script, line by line. The first cryptic line says that it’s a script that is executed by the Linux shell. The next line is empty, followed by five lines that are the instructions to the scheduler (they start with #PBS):
-Nspecifiies the name of the job;- the first
-lline is the specification of resources: one node, ten CPUs, ten Gb of RAM, 1g interconnect; - the second
-lline is the amount of walltime (twenty minutes); -qspecifies the name of the queue;-ospecifies the name of the output file where the Matlab output will be printed;-j oemeans “join output and error”, which is, if any errors happen, they will be written intorandom_matrix.txt.
The rest is the instructions what to do once we get on the compute node that satisfies the request we provided in -l: go to the directory from which you have submitted qsub, load the R module, and execute the R script called randmatrix.r that we have created. Save the PBS script and exit nano (Ctrl+O, ENTER, Ctrl+X).
A very common question is how much walltime we should ask for. It’s a tricky question beause there is no way of knowing how much time you will need until you actually try it. My rule of thumb is: make a rough guess, and ask for twice as much.
Now, let’s submit our batch job!
qsub randmatrix.sh
We use the same command qsub that we have previously used for an interactive job, but now it’s much simpler, because all the hard work went into creating the PBS shell script randmatrix.sh and qsub reads all the necessary information from there. If the submission was successful, it will give you the job ID, for example:
632585.pbs02
We can monitor the job’s progress with the qstat command. This is an example to list all jobs that are currently executed by you:
qstat -u <your Palmetto username>
You should see something like this:
pbs02:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
632585.pbs02 gyourga skystd* random_matrix 24385* 1 10 10gb 00:20 R 00:00
You see the job ID, your Palmetto username, the name of the queue (more on that later), the name of the job (random_matrix), the resources requested (1 node, 10 CPUs, 10 gb of RAM, twnety minutes of walltime). The letter R means that the job is running (Q means “queued”, and F means “finished”), and then it shows for how long it’s been running (it basically just started).
Wait a little bit and do qstat again (you can hit the UP arrow to show the previous command). Elap time should now be a bit longer. The script should take five minutes or so to execute. If you enter qstat -u <your Palmetto username> and the list is empty, then congratulations, we are done!
If everything went well, you should now see the file random_matrix.txt. Let’s print it on screen:
cat random_matrix.txt
[,1] [,2] [,3] [,4]
[1,] 0.33798012 -0.12144303 0.28047223 0.3158535
[2,] -0.20359725 1.24607176 -0.04659389 0.6236961
[3,] 1.21438131 -0.33665263 -1.34250195 0.1748334
[4,] -0.01764249 -0.07867804 -0.74425883 0.7559597
Your matrix might be different because it’s a random matrix.
Another way to use qstat is to list the information about a particular job. Here, instead of -u, we use the -xf option, followed by the Job ID:
qstat -xf 632585
This will give you a lot of information about the job, which is really useful for debugging. If you have a problem and you need our help, it is very helpful to us if you provide the job ID so we can do qstat -xf on it and get the job details.
How many jobs can you run at the same time? It depends on how much resources you ask for. If each job asks for a small amount of resources, you can do a large amount of jobs simultaneously. If each job needs a large amount of resources, only a few of them can be running simultaneously, and the rest of them will be waiting in the queue until the jobs that are running are completed. This is a way to ensure that Palmetto is used fairly.
These limits of the number of simultaneous jobs is not carved in stone, but it changes depending on how much Palmetto is used at the moment. To see the current queue configuration, you can execute this command (note that it only works on the login node):
checkqueuecfg
You will see something like this:
1G QUEUES min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
c1_solo 1 1 10000gb 1000 336:00:00
c1_single 2 24 30000gb 250 336:00:00
c1_tiny 25 128 51200gb 50 336:00:00
c1_small 129 512 8192gb 2 336:00:00
c1_medium 513 2048 16384gb 1 336:00:00
c1_large 2049 4096 32768gb 1 336:00:00
IB QUEUES min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
c2_single 1 40 4000gb 10 72:00:00
c2_tiny 41 200 16000gb 5 72:00:00
c2_small 201 512 12288gb 2 72:00:00
c2_medium 513 2048 16384gb 1 72:00:00
c2_large 2049 4096 0gb 0 72:00:00
GPU QUEUES min_gpus_per_job max_gpus_per_job min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
gpu_small 1 4 1 96 2880gb 10 72:00:00
gpu_medium 5 16 1 256 4608gb 3 72:00:00
gpu_large 17 256 1 2048 6144gb 1 72:00:00
SMP QUEUE min_cores max_cores max_jobs max_walltime
bigmem 1 80 5 168:00:00
SKYLIGHT QUEUES max_jobs max_walltime
skystd_e 10 240:00:00
skylm_e 3 240:00:00
skygpu_e 5 240:00:00
The relevant information is the thre skylight queues at the bottom. Maximum walltime for Skylight users is 240 hours (10 days). Maximum number of jobs that can be executed in parallel is 10 for skystd, 3 for skylm, and 5 for skygpu. These numbers can be changed in future, so make sure you run checkqueuecfg once in a while to see if the limits have changed.
Key Points
batch jobs don’t require interaction with the user and run on the compute nodes on the background
to submit a batch job, users need to provide a PBS script which is passed to the scheduler
jobs are assigned to queues, according to the amount of requested resources
different queues have different limits on the walltime and the number of parallel jobs
Web-based access to the Palmetto Cluster
Overview
Teaching: 15 min
Exercises: 0 minQuestions
How can I access the Palmetto cluster from a web browser?
Objectives
Logging into Palmetto from a browser.
We have an interface to Palmetto that works through a Web browser. This interface is called “Open On Demand”, or OpenOD for short. To access it, go to
https://openod02.palmetto.clemson.edu
You will need to login with your Clemson username and password, and perform a DUO check.
One convenient feature of Open OnDemand is a file browser. In the top left corner, you will see the “Files” button, which will take you to your home diretory or to scratch directory. Click it and explore the files in your file system. You can use this feature to view, edit, and delete files. It is also a convenient way to upload and download the files. You can go to any folder that you have access to by clicking “Go to”.
You can also use the web interface to run a terminal on Palmetto. This way, OpenOD becomes an alternative to MobaXTerm or to the Mac Terminal application. To start the terminal, click on Clusters, then Palmetto Shell Access:
Enter your account password and do the two-factor identification. This will bring you to the login node of Palmetto:
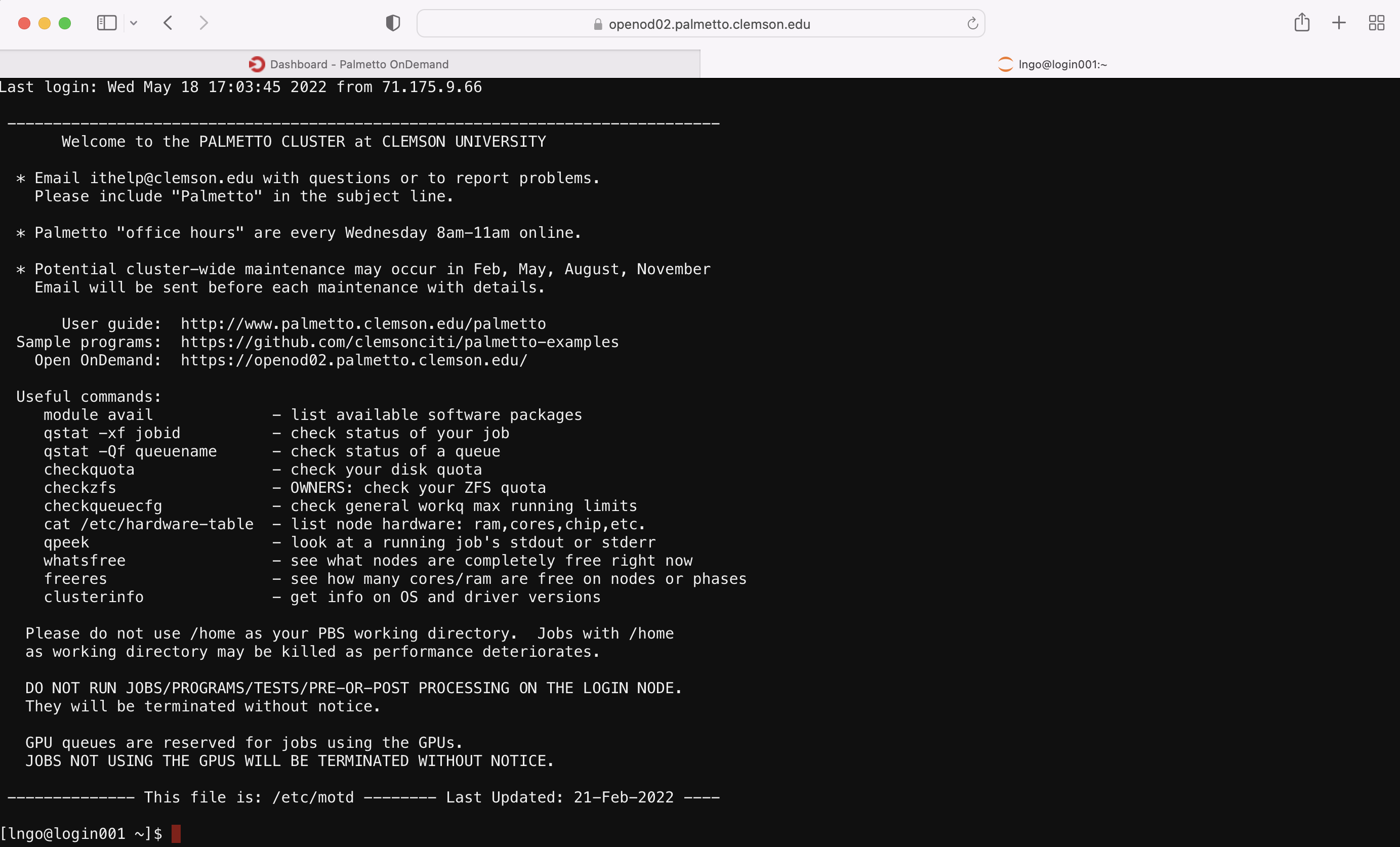
From here, you can run scripts on the login node (such as checkquota, checkqueucfg, whatsfree), and request compute nodes with qsub.
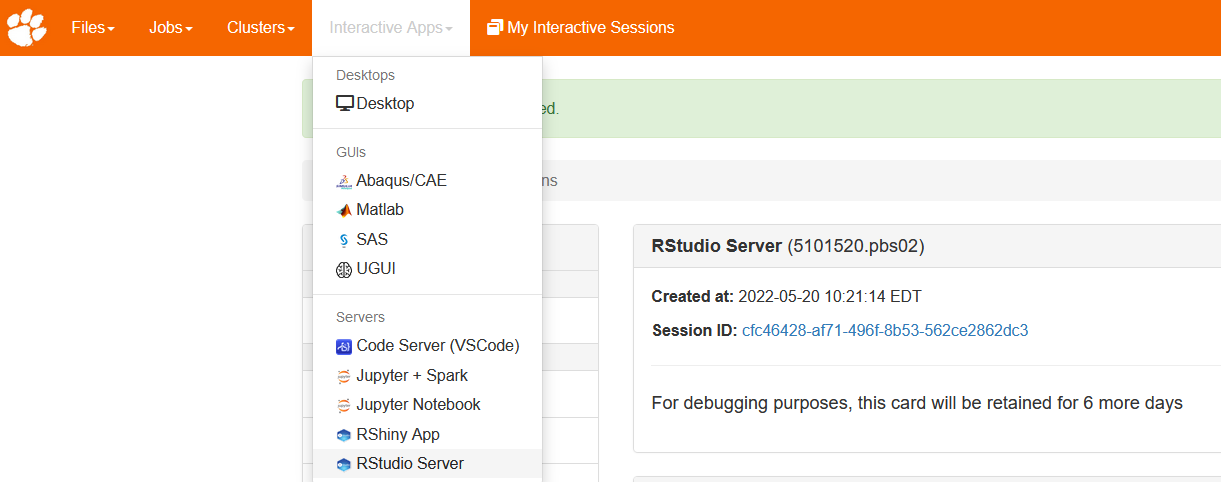
You can use OpenOD to run certain applications like Jupyter and Tensorflow notebooks, R Studio, and Matlab. Let’s run R Studio. From “Interactive apps”, please select “RStudio server”:
Please fill out the request as shown on this picture (make sure the queue is set to skystd or to skylm):
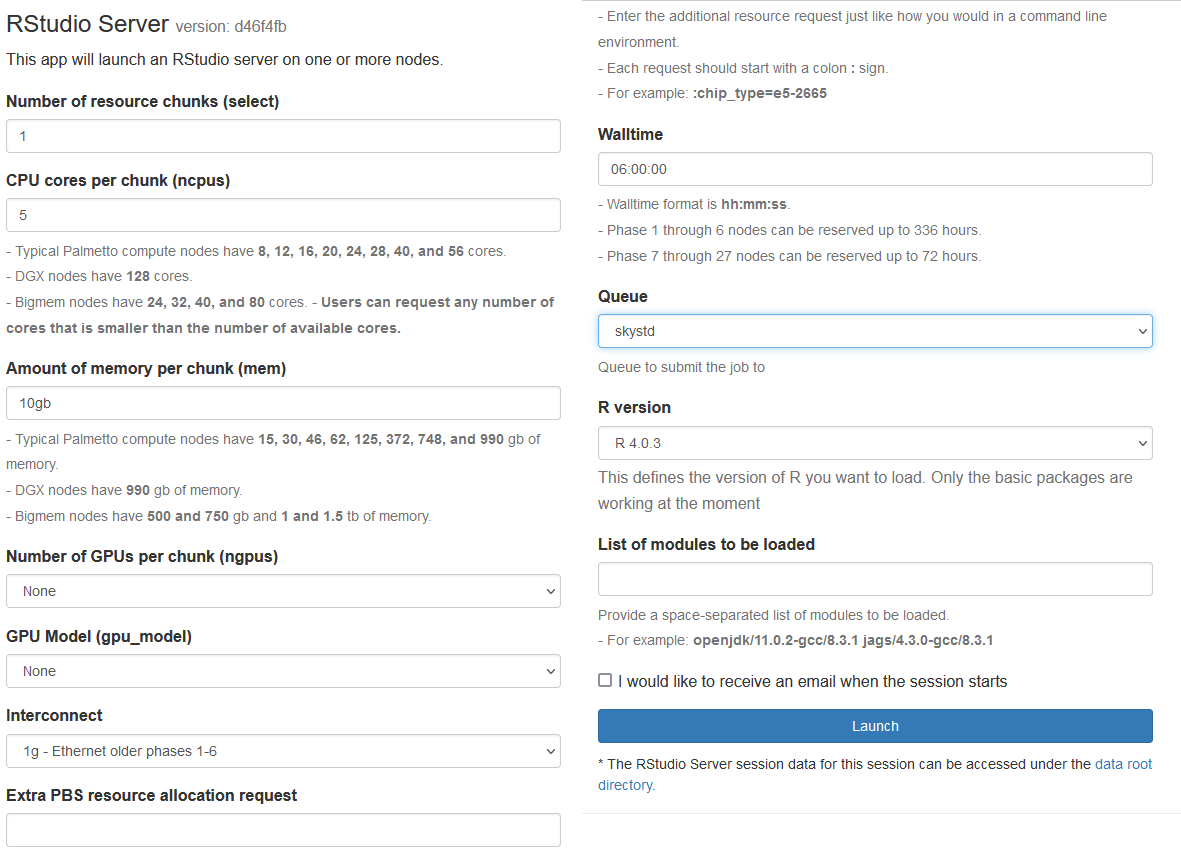
This is basically a graphical interface to qsub. You are asking for 1 compute node, 5 CPUs, 10 GB of memory, no GPU, 1g interconnect (that is, a c1 node), for the walltime duration of 6 hours. Once you are done entering this information, please click the blue “Launch” button at the bottom. It will bring out a new screen:
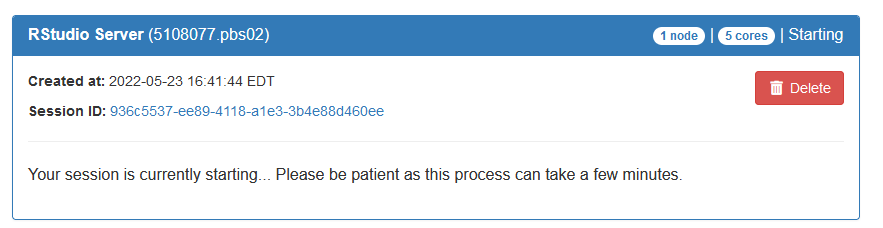
This means your request is being processed. Once the compute node is ready, you will see a blue button under your request saying “Connect to RStudio server”:
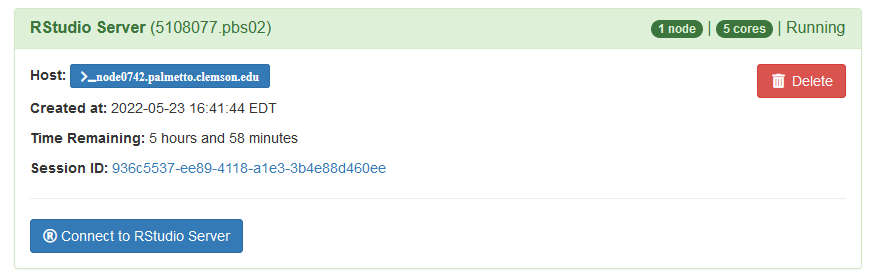
Click on it, and it will start RStudio.
We won’t go further into R Studio at this workshop, but if you are interested, please attend our “Introduction to R” workshop.
Thank you for your attention!
Key Points