Computer Vision and Convolutional Neural Networks#
In 2012, Alex Krizhevsky et al. competed in the ImageNet Large Scale Visual Recognition Challenge. Their solution, based on a deep Convolutional Neural Network (CNN) beat the runner up by more than 10% (their paper). Prior to this result, many thought that it was infeasable to train such deep models due to the large number parameters that need to be optimized and the associated high computational cost. Krizhevsky et al. were among the first to user GPUs to speed things up. This landmark result kicked off a wave of innovation that continues to this day.
Convolutional Neural Networks are named thus because of the convolution operation which plays a primary role in their design. You can take a look at these slides to get a sense for what the convolution operator does. Convolution is a great example of building inductive biases into the network architecture. In this case, the inductive priors are locality and translation invariance. These assumptions lead to weight sharing which significantly improves the parameter efficiency of our model relative to the fully connected neural networks that we’ve seen so far.
In this notebook, we apply CNNs to the classification of handwritten characters (letters and numbers) using the EMNIST dataset. The EMNIST dataset has the digits 0 through 9 and a total of 37 upper and lower-case latin characters (see Figure) for a total of 47 classes. The latin characters make EMNIST a more difficult classification task than the more famous MNIST dataset which only contains digits. We will work through a variety of architecture design considerations, will train the model for each case, and learn to reason about how architecture choices impact the performance characteristics of the model.
Setup#
# Library imports
import os
import numpy as np
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import matplotlib.pyplot as plt
from PIL import Image
import math
%matplotlib inline
# set random seed for reproducibility
_ = torch.manual_seed(0)
For more information about Palmetto storage, see the onboarding training and the documentation for Palmetto storage.
# save locations
# best not to use your home directory for reading/writing large temporary files
# /scratch is much faster!
data_dir = f"/scratch/{os.environ['USER']}/data"
model_path = f"/scratch/{os.environ['USER']}/model.pt"
# Model and Training
batch_size=64 #input batch size for training (default: 64)
test_batch_size=1000 #input batch size for testing (default: 1000)
num_workers=9 # parallel data loading to speed things up
lr=1.0 # learning rate
gamma=0.7 # Learning rate step gamma (default: 0.7)
no_cuda=False #disables CUDA training (default: False)
seed=42 #random seed (default: 42)
log_interval=10 #how many batches to wait before logging training status (default: 10)
save_model=False #save the trained model (default: False)
# additional derived settings
use_cuda = not no_cuda and torch.cuda.is_available()
torch.manual_seed(seed)
device = torch.device("cuda" if use_cuda else "cpu")
print("Device:", device)
Device: cuda
# Loading the data
# Pytorch provides a number of pre-defined dataset classes
# EMNIST is one of them! Pytorch will automatically download the data.
# It will only download if the data is not already present.
data_train = datasets.EMNIST(data_dir, split='balanced', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
data_test = datasets.EMNIST(data_dir, split='balanced', train=False, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
# define pytorch dataloaders for training and testing
train_loader = torch.utils.data.DataLoader(data_train, batch_size=batch_size, shuffle=True, num_workers=num_workers, pin_memory=True)
test_loader = torch.utils.data.DataLoader(data_test, batch_size=test_batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
# save a test batch for later testing
image_gen = iter(test_loader)
test_img, test_trg = next(image_gen)
print("Training dataset:", train_loader.dataset)
print("Testing dataset:", test_loader.dataset)
Training dataset: Dataset EMNIST
Number of datapoints: 112800
Root location: /scratch/cehrett/data
Split: Train
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.1307,), std=(0.3081,))
)
Testing dataset: Dataset EMNIST
Number of datapoints: 18800
Root location: /scratch/cehrett/data
Split: Test
StandardTransform
Transform: Compose(
ToTensor()
Normalize(mean=(0.1307,), std=(0.3081,))
)
# Look at some examples
n_images = 16
rand_imgs = next(iter(test_loader))
ints = torch.randint(0,len(rand_imgs[0]), (n_images,))
fig, ax_arr = plt.subplots(4, 4)
ax_arr = ax_arr.flatten()
for n, ix in enumerate(ints):
img = rand_imgs[0][ix]
ax_arr[n].imshow(img[0].detach().cpu().numpy().T, cmap='Greys')
ax_arr[n].axis('off')
plt.tight_layout()
plt.show()

Question: In addition to the larger number of classes in EMNIST compared to MNIST, why might it be more difficult to accurately classify images from the EMNIST set?
# Training and testing functions
def train(model, device, train_loader, optimizer, epoch):
model.train()
losses = []
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('\r\tTrain epoch {}: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()), end='')
def test(model, device, test_loader, epoch):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\rTest epoch {}: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)'.format(
epoch,
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def train_and_test(model, save_name=model_path, epochs=5):
# Train the linear model
optimizer = optim.Adadelta(model.parameters(), lr=lr)
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
for epoch in range(1, epochs + 1):
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader, epoch)
scheduler.step()
if save_model:
torch.save(model.state_dict(), save_name)
def get_n_params(model): return sum(p.numel() for p in model.parameters())
Classification architectures#
We will explore a range of classification architectures starting with a linear classifier and scaling up to a several-layer convolutional neural network. Each architecture can be described in two steps (see figure below):
Feature extraction – converting the raw pixel information into a feature vector
Classification – converting the feature vector into predictions about the character in the input image.
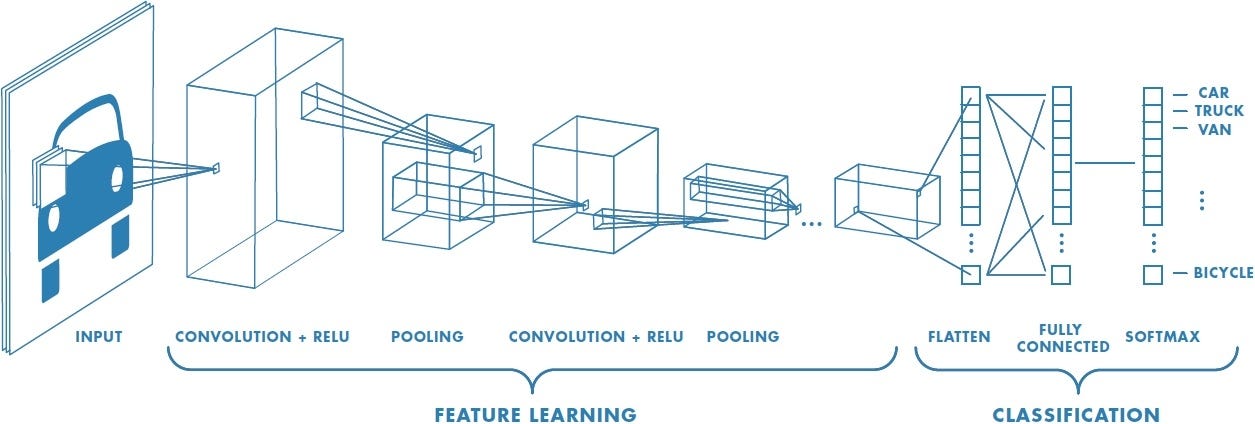
Most of the secret sauce of CNNs takes place in the feature extraction step. We will define a generic classification architecture that takes as input the sequence of operations used for feature extraction. We will use progressively more complex feature extraction pipelines. For the classification step, we will always use a single linear layer, but the number of inputs will depend on the size of the feature vector produced by the feature extractor.
The class defined below implements this generic classifier class in pytorch.
# Define the generic EMNIST classification architecture
# The `feature_extractor` argument takes images as input and produces feature vectors.
# These vectors can be of any length.
class Classifier(nn.Module):
def __init__(self, feature_extractor):
super(Classifier, self).__init__()
# feature encoder
self.feature_extractor = feature_extractor
# classifier
# LazyLinear allows input size to be inferred automatically
self.classifier = nn.LazyLinear(47) # 47 classes in EMNIST
def forward(self, x):
x = self.feature_extractor(x) # Flatten -> x_i
x = self.classifier(x) # Matrix multiply -> c_m^0 + sum(W_mi*x_i)
x = F.softmax(x, dim=1) # apply the softmax function
return x
Linear Classifier#
A linear classifier uses the original pixels as the features for classification. We simply need to unravel the 2D image into a vector. This is accomplished using nn.Flatten().
Note: you can safely ignore the message UserWarning: Lazy modules are a new feature under heavy development so changes to the API or functionality can happen at any moment. warnings.warn('Lazy modules are a new feature under heavy development
# set random seed for reproducibility
torch.manual_seed(0)
# define the feature extractor
# for linear model, we just flatten the original image into a vector
feature_extractor = nn.Flatten()
# Create the model
model = Classifier(feature_extractor).to(device)
# Display model and number of parameters
# Run one batch through the model to initialize the lazy linear layer
# this is necessary to get accurate parameter counts
with torch.no_grad():
model(test_img.to(device))
display(model)
print("Number of parameters in linear model:", get_n_params(model))
Classifier(
(feature_extractor): Flatten(start_dim=1, end_dim=-1)
(classifier): Linear(in_features=784, out_features=47, bias=True)
)
Number of parameters in linear model: 36895
Train and test the linear model#
train_and_test(model)
# by default, `train_and_test` trains for 5 epochs
# you can adjust this using the epochs argument, like
# train_and_test(model, epochs=2)
Test epoch 1: Average loss: 3.3020, Accuracy: 11264/18800 (59.91%)
Test epoch 2: Average loss: 3.2766, Accuracy: 11716/18800 (62.32%)
Test epoch 3: Average loss: 3.2662, Accuracy: 11899/18800 (63.29%)
Test epoch 4: Average loss: 3.2604, Accuracy: 11989/18800 (63.77%)
Test epoch 5: Average loss: 3.2485, Accuracy: 12224/18800 (65.02%)
Question: Think of a naive performance baseline for this task. How well does it compare with that performance? Do you find this suprising given that this is just a linear model?
CNN Classifier#
One convolution layer#
We now make a more interesting feature extractor using convolution. The feature extractor has the following steps:
convolution (
nn.Conv2d) over the input image.batch normalization (
nn.BatchNorm2d) rescales the feature maps. This helps the network converge more quickly. You can see the definition here.max pooling (
nn.MaxPool2d) takes the maximum pixel from each 2x2 block resulting in an image that has half the size in each dimension.ReLU (
nn.ReLU) zeroes out negative values in the feature maps. See figure:

# set random seed for reproducibility
torch.manual_seed(0)
# define the feature extractor
feature_extractor = nn.Sequential(
# convolution block:
nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, bias=False),
nn.LazyBatchNorm2d(),
nn.ReLU(),
nn.MaxPool2d(2),
# flatten just as with the linear classifier
nn.Flatten()
)
# Create the model
model = Classifier(feature_extractor).to(device)
# @title Display model and number of parameters
# Run one batch through the model to initialize the lazy linear layer
# this is necessary to get accurate parameter counts
with torch.no_grad():
model(test_img.to(device))
display(model)
print("Number of parameters in linear model:", get_n_params(model))
Classifier(
(feature_extractor): Sequential(
(0): Conv2d(1, 4, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Flatten(start_dim=1, end_dim=-1)
)
(classifier): Linear(in_features=676, out_features=47, bias=True)
)
Number of parameters in linear model: 31863
(Less than 36,895 for linear model)
from utils import create_answer_box
create_answer_box("Why do you think the CNN has fewer parameters than the linear model?", "07-01")
Why do you think the CNN has fewer parameters than the linear model?
train_and_test(model)
Test epoch 1: Average loss: 3.2316, Accuracy: 12464/18800 (66.30%)
Test epoch 2: Average loss: 3.1804, Accuracy: 13402/18800 (71.29%)
Test epoch 3: Average loss: 3.1570, Accuracy: 13813/18800 (73.47%)
Test epoch 4: Average loss: 3.1459, Accuracy: 14035/18800 (74.65%)
Test epoch 5: Average loss: 3.1420, Accuracy: 14099/18800 (74.99%)
create_answer_box("Why do you think the CNN beats the linear model after 5 epochs despite having fewer parameters?", "07-02")
Why do you think the CNN beats the linear model after 5 epochs despite having fewer parameters?
Feature maps: let’s look at the internal representations of the images produced by the 4 convolution kernel. In the picture below, the colored grids on the left are representations of the convolution kernel matrices. The values of these kernel matrices were “learned” during the training of the network. The image on the right is the feature map produced by convolving the kernel matrix with the original image. Bright areas correspond to high numerical values; dark areas correspond to low numerical values. Rerun the cell to see the feature maps for different images.
imgs, labels = next(image_gen)
test_img_plot = imgs[6,0]
kern = model.feature_extractor[0]
# Generate feature maps
fmaps_1 = kern(test_img_plot[None, None].cuda()).detach().cpu().numpy()[0]
for K, fmap in zip(kern.weight, fmaps_1):
# plot kernel
plt.subplot(1,2,1)
mat = K.clone().detach().cpu().numpy()[0]
plt.imshow(mat.T)
plt.axis('off')
# plot feature map
plt.subplot(1,2,2)
plt.imshow(fmap.T, cmap='Greys')
plt.axis('off')
plt.show()


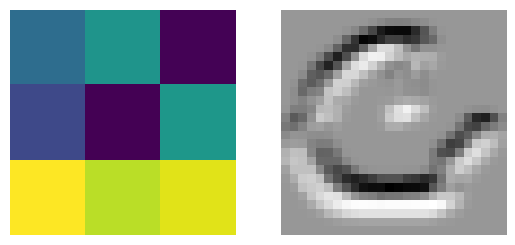

A “wider” model#
The “width” of a CNN refers to how many feature maps are used in the convolution layers. Wide layers have many convolution kernels leading to many feature maps. In the model above, we had 4 convolution kernels (see out_channels=4 in the nn.Conv2d layer in the feature extractor). Interpreting these kernels as feature extractors, it’s plausible that we could improve the performance of the model by increasing the number of kernels.
The network below is the same as the previous one except that it uses twice as many kernels.
# set random seed for reproducibility
torch.manual_seed(0)
# define the feature extractor
feature_extractor = nn.Sequential(
# convolution block:
nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3, stride=1, bias=False),
nn.LazyBatchNorm2d(),
nn.ReLU(),
nn.MaxPool2d(2),
# flatten just as with the linear classifier
nn.Flatten()
)
# Create the model
model = Classifier(feature_extractor).to(device)
# @title Display model and number of parameters
# Run one batch through the model to initialize the lazy linear layer
# this is necessary to get accurate parameter counts
with torch.no_grad():
model(test_img.to(device))
display(model)
print("Number of parameters in linear model:", get_n_params(model))
Classifier(
(feature_extractor): Sequential(
(0): Conv2d(1, 8, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(4): Flatten(start_dim=1, end_dim=-1)
)
(classifier): Linear(in_features=1352, out_features=47, bias=True)
)
Number of parameters in linear model: 63679
Notice that doubling the number of channels nearly doubled the number of free parameters in the model.
train_and_test(model)
/home/cehrett/.conda/envs/PytorchWorkshop/lib/python3.11/site-packages/torch/utils/data/dataloader.py:557: UserWarning: This DataLoader will create 9 worker processes in total. Our suggested max number of worker in current system is 8, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.
warnings.warn(_create_warning_msg(
Test epoch 1: Average loss: 3.1864, Accuracy: 13286/18800 (70.67%)
Test epoch 2: Average loss: 3.1305, Accuracy: 14327/18800 (76.21%)
Test epoch 3: Average loss: 3.1130, Accuracy: 14641/18800 (77.88%)
Test epoch 4: Average loss: 3.1035, Accuracy: 14845/18800 (78.96%)
Test epoch 5: Average loss: 3.0976, Accuracy: 14930/18800 (79.41%)
create_answer_box("The performance of the 8-kernel model is better than the 4-kernel model, but only a little better. Why do you the 8-kernel model achieves better performance than the 4-kernel? (And why isn't it MUCH better?)", "07-03")
The performance of the 8-kernel model is better than the 4-kernel model, but only a little better. Why do you the 8-kernel model achieves better performance than the 4-kernel? (And why isn’t it MUCH better?)
A “deeper” model#
The “depth” of a CNN refers to how many convolution layers are used in the network. The feature maps from one convolution step are used as the input for the next convolution. The previous network had a single convolution step. We will now try adding more convolution layers and see how it effects performance. To isolate the effect of having more layers, we will hold the width at 4 kernels like our first CNN.
Question: Why might it be helpful to add more convolutional layers to the CNN? Can you contrast the effect of adding more depth to the effect of greater width?
# set random seed for reproducibility
torch.manual_seed(0)
# define the encoder
# we repeat the convolution block several times
feature_extractor = nn.Sequential(
# block 1
nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, stride=1, bias=False),
nn.LazyBatchNorm2d(),
nn.ReLU(),
# 2
nn.Conv2d(in_channels=4, out_channels=4, kernel_size=3, stride=1, bias=False),
nn.LazyBatchNorm2d(),
nn.ReLU(),
# 3
nn.Conv2d(in_channels=4, out_channels=4, kernel_size=3, stride=1, bias=False),
nn.LazyBatchNorm2d(),
nn.ReLU(),
nn.MaxPool2d(2),
# flatten just as with the linear classifier
nn.Flatten()
)
# Create the model
model = Classifier(feature_extractor).to(device)
# @title Display model and number of parameters
# Run one batch through the model to initialize the lazy linear layer
# this is necessary to get accurate parameter counts
with torch.no_grad():
model(test_img.to(device))
display(model)
print("Number of parameters in linear model:", get_n_params(model))
Classifier(
(feature_extractor): Sequential(
(0): Conv2d(1, 4, kernel_size=(3, 3), stride=(1, 1), bias=False)
(1): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), bias=False)
(4): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
(6): Conv2d(4, 4, kernel_size=(3, 3), stride=(1, 1), bias=False)
(7): BatchNorm2d(4, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Flatten(start_dim=1, end_dim=-1)
)
(classifier): Linear(in_features=484, out_features=47, bias=True)
)
Number of parameters in linear model: 23143
create_answer_box("The number of parameters is actually _less_ than our single layer model. We added lots of convolution kernels, so how can that be?", "07-04")
The number of parameters is actually less than our single layer model. We added lots of convolution kernels, so how can that be?
train_and_test(model)
create_answer_box("You should find that the deeper model performed similarly to the wider model despite having many fewer parameters. Why do you think increasing the depth of the model was more parameter efficient than increasing the width?", "07-05")
You should find that the deeper model performed similarly to the wider model despite having many fewer parameters. Why do you think increasing the depth of the model was more parameter efficient than increasing the width?
Your turn!#
Modify the feature extractor below and see how good of a score you can obtain on EMNIST. Some ideas:
Change the number of channels in the convolution layers. Note: the
in_channelsargument tonn.Conv2dmust match theout_channelsargument from a previous layer. The input image has 1 channel since the images are grayscale.Change the
kernel_size, which is the size of the kernel matrix used in convolution.Change the number of convolution blocks in the network.
Add or remove max pooling layers between convolution blocks
Use a greater number of epochs in the
train_and_testfunctionAdvanced: can you figure out how to add “residual”/”skip” connections? See this paper.
There are many, many possible combinations that you could try, and you can’t explore them all. Try to think of a few experiments to try and record what you learn. If you want to go down the rabbit hole of trying many things, feel free, but that’s not expected for this assignment.
Try to beat my score of ~80% resulting from using the “deeper model” above trained for 13 epochs.
# set random seed for reproducibility
torch.manual_seed(355)
# define the encoder -- feel free to check the above code for hints and ideas
feature_extractor = nn.Sequential(
...
)
# Create the model
model = Classifier(feature_extractor).to(device)
train_and_test(model, epochs=13)
create_answer_box("What accuracy did you achieve?", "07-06")
create_answer_box("Please copy/paste the code of your feature extractor here so we can see your architecture.", "07-07")
What accuracy did you achieve?
Please copy/paste the code of your feature extractor here so we can see your architecture.