Data Partition with caret#
Data partition: training and testing#

In a typical machine learning problem, you have a data set and you need to create a model which predicts the outcomes.
You can use all the available data for training the model (that is, learning the associations between the data and the outcomes), and
then you can just keep your fingers crossed and hope that your model will perform well when it will be applied to data that it has never seen before.
A more realistic behaviour is to reserve some of the data for testing the model. That is, you split the data into two sets: a training set and a testing set.
You use the training set to train the model, and
then you apply the test set to get an estimate on how well the model works on the data that were not used for training. This is called cross-validation.
It is absolutely critical that the training and test sets are completely independent. Otherwise, when you test your model, your prediction accuracy will be artificially high – not because your model is good, but because there is some correlation between the training and test sets.
The more data you have for training, the more hope you can have that the model will accurately capture the relationships between the inputs and the outcomes. The more data you have for testing, the more accurate is your estimate on how well your model generalizes. So splitting the data into training and test sets is not a trivial task, with a lot of research performed on it. Some strategies are:
leave-one-out cross-validation (“LOO”). Here, we maximize the training set: only one observation is used for test, and remaining observations are used for training. This is done in a loop, so each observation gets its turn to be in the test set. This procedure is common when you work with small datasets.
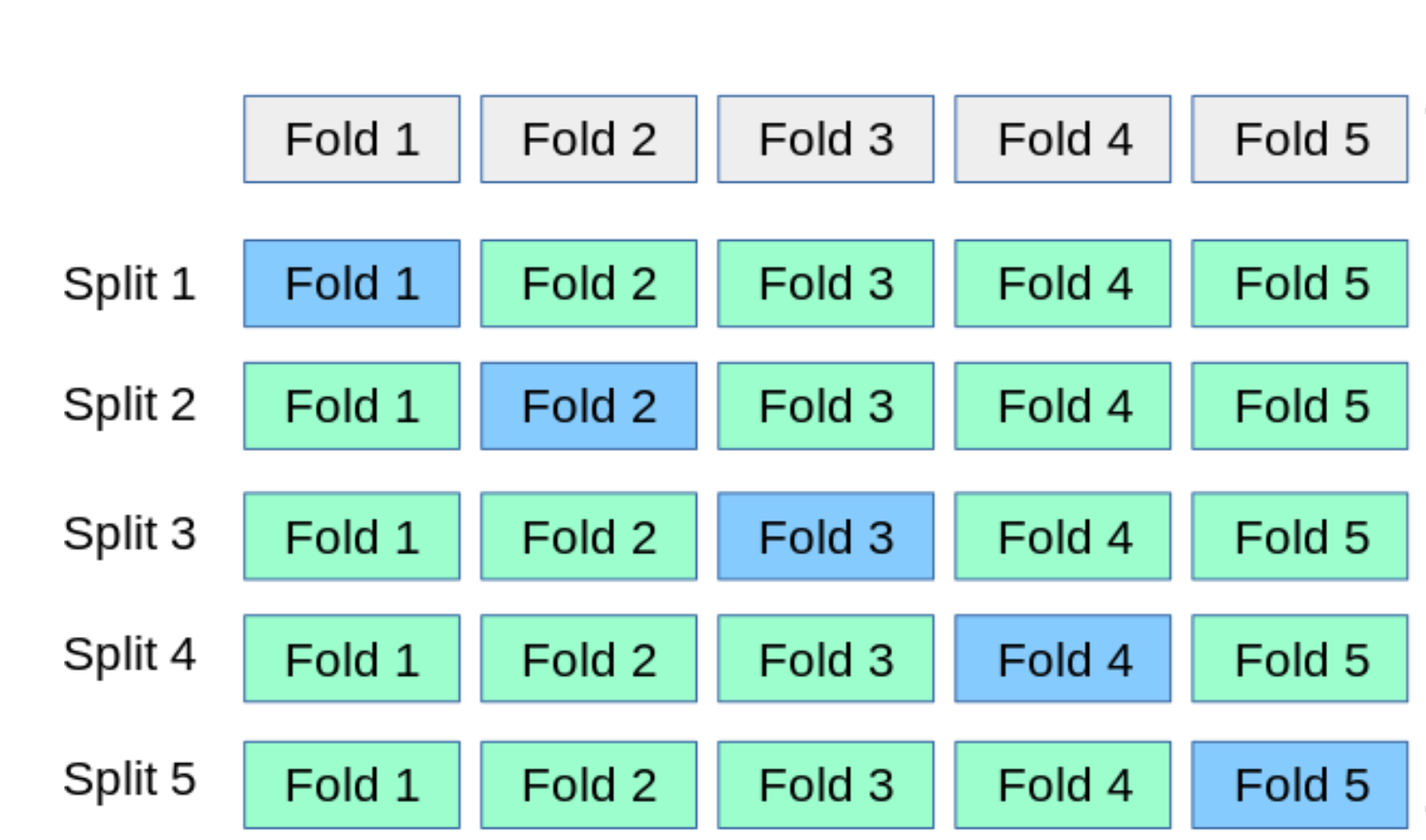
80-20 split: 80% of the data are used for training, and 20% for testing. Again, this is done in a loop. One strategy is to get a random sample of 20% of the data, in a loop; at the next iteration, you can get another random sample of 20% etc. Another strategy is to first use the first 20%, at the next iteration you use the next 20%, etc; this way, you can have 5 iterations to go through the whole data set. This is also called 5-fold cross-validation.
A general idea of k-fold cross-validation is to break up the data into
kchunks and, at each iteration, use one of the chunks for testing and the rest of the data for training.
split-half: the data are evenly split into training and test sets. First, you use on half for trainig and the other for testing; second, you use the second half for training and the first half for testing. The amount of training data is relatively small, but this way is sometimes used if the stability of the model is just as important as the classification accuracy.
Here we use
createDataPartitionto randomly split 60% data for training and the rest for testing:

ind1 <- createDataPartition(y=iris$Species,p=0.6,list=FALSE,times=1)
#list=FALSE, prevent returning result as a list
#times=1 to create one split
training <- iris[ind1,]
testing <- iris[-ind1,]
Data spliting using K-fold: Cross validation approach#
The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. As such, the procedure is often called k-fold cross-validation. When a specific value for k is chosen, it may be used in place of k in the reference to the model, such as k=10 becoming 10-fold cross-validation.

fitControl <- trainControl(method="cv", number=10)
# train the model
model <- train(Species~., data=training,
trControl=fitControl, method="lda")
# summarize results
print(model)
predict1 <- predict(model,testing)
More information on model tuning using caret can be found here