Other LLM Topics#
In this workshop we focused on understanding the core ideas of the Language Modeling and the Transformer Architecture. The community has built many methods and tools around these core ideas. In this notebook we list some of the most important ideas. This is by no means complete!
From here to ChatGPT#
How do we get from the humble language model we developed today to something as powerful as ChatGPT?
There are 3 primary ingredients. The first two are boring:
Scale and quality of the training data (~ Million times larger)
Scale of the model (number and size of transformer blocks) (10s of thousands of times larger)
Human preference training
Obviously this all takes a lot more compute resources than we have here. For instance, X’s Grok LLM was trained using 8000 A100 gpus.
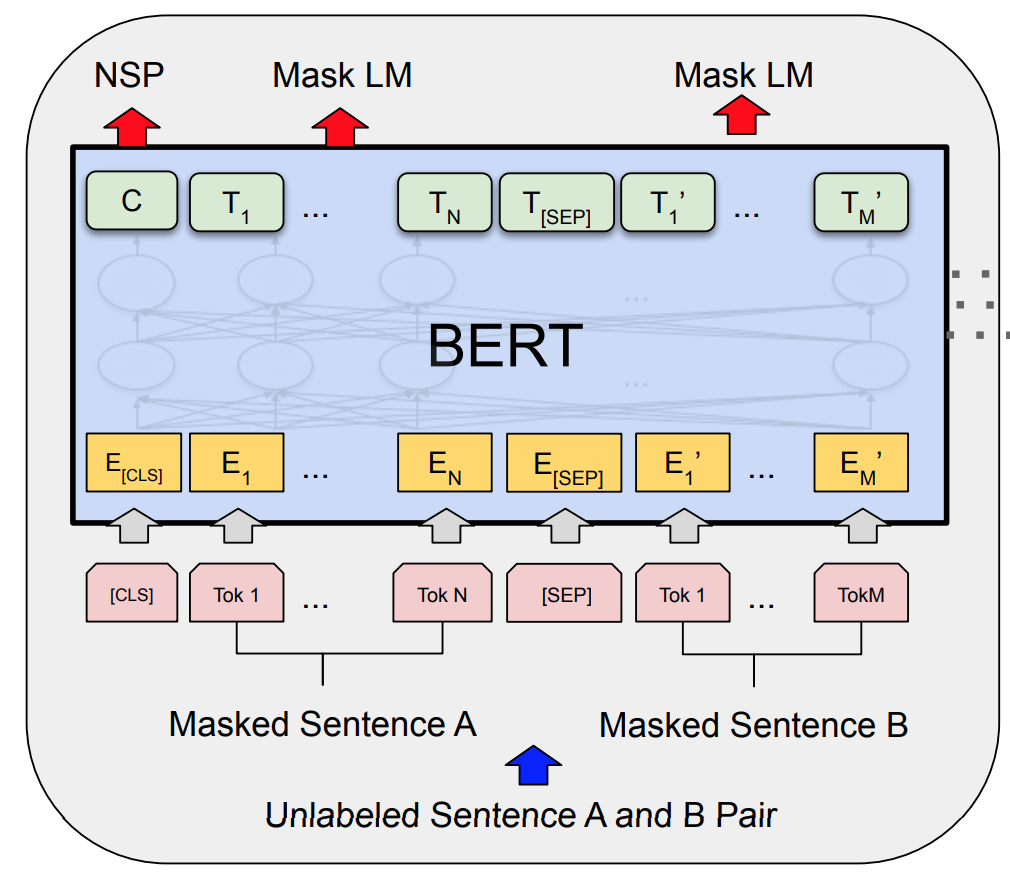
Masked language modeling#
So far, we’ve only discussed Autoregressive Language Modeling. This is the kind used for generating text, like ChatGPT. Another important class of language models are “Masked Language Models” as introduced by BERT (see figure). Masked language models are useful when fine-tuning on small datasets.
How would we have to change our attention masking to accomodate masked language modeling?
🤗 Huggingface#
We used Huggingface tools for the data prep. It’s way bigger than that. The Huggingface Hub has become the de-facto place to upload pretrained LLMs. To date, they have more than 31,000 autoregressive language models uploaded. In addition, the Huggingface APIs make it easy to load any of these models and fine tune them on your own data. For instance the AutoModelForCausalLM class allows you to download a model from the Hub for use as a Causal/Autoregressive language model. You can then use the Trainer class to fit the model to your data. These tools make it much easier to experiment with a wide variety of new language models.
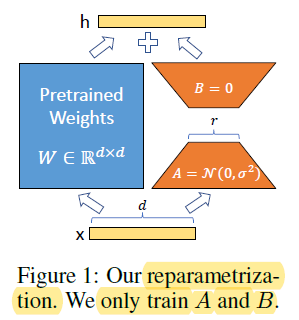
Low-rank adaptation (LoRA)#
Fine tuning refers to adapting a pre-trained LLM to a small, domain-specific dataset. As mentioned, Huggingface provides convenient tools for this fine tuning. However, some models are so large, that it is prohibitively computationally intensive to fine tune. There are a number of techniques to address this. Perhaps the most widely applied is Low-rank adaption (LoRA). The basic idea is simple. Rather than fine tune all of the network weight matrices, we will only fine tune some of them. In addition, rather than fine tune full-rank weight matrices, we fine-tune low-rank weight matrices. See picture for the idea.
Model quantization#
Lora helps reduce the amount of compute needed to fine-tune an LLM. However, many LLMs may still be too large to fit in VRAM. Quantization reduces model size by re-expressing the trained LLM into lower-precision weights. This can lead to factor of 2 or 4 reductions in the memory footprint. Quantization and LoRA are often used together. Using these techniques, LLMs can be fine tuned on CPU, on with hybrid mixtures of CPU and GPU, and can even make use of Swap memory.