Running a batch job#
Interactive jobs are great if you need to do something quick, or perhaps visualize some data. If you have some code which runs for seven hours, interactive jobs are not a great idea. Please keep in mind that an interactive job gets killed if you close the SSH connection. So for example, you connect to Palmetto from your laptop, start an interactive job, but then your laptop runs out of battery power and you can’t find your charger. SSH client quits, and your interactive job is killed.
If you have some truly serious, multi-hour computation project (and that’s what Palmetto is really good for), a better idea is to run it on the background. This is called a batch job. You submit it in a fashion which is conceptually similar to an interactive job, but then it runs on the compute node on the background until it’s over. If it needs to take two days, it takes two days. You can quit the SSH client or close your laptop, it won’t affect the batch job.
To submit a batch job, we usually create a separate file called a PBS script. This file asks the scheduler for specific resources, and then specifies the actions that will be done once we get on a compute node.
Let us go through an example. We will use batch mode to create a small random matrix with normally-distributed values. We will create two scripts: an R script which does the computation, and a PBS script which will execute the R script on a compute node in batch mode.
Palmetto has a simple text editor which is called nano. It doesn’t offer any fancy formatting, but it suffices for ceating and editing simple texts. Let’s go to our home directory and create the R script:
cd
nano randmatrix.r
This will open the nano text editor:
Fig. 20 Nano just opened with empty file.#
Inside the editor, type this:
size <- 5000
M <- matrix(rnorm(size*size), nrow=size)
ev <- eigen(M)
values <- ev$values
values[1]
Instead of typing, you can copy the text from the Web browser and paste it into nano. Windows users can paste with Shift+Ins (or by right-clicking the mouse). Mac users can paste with Cmd+V. At the end, your screen should look like this:
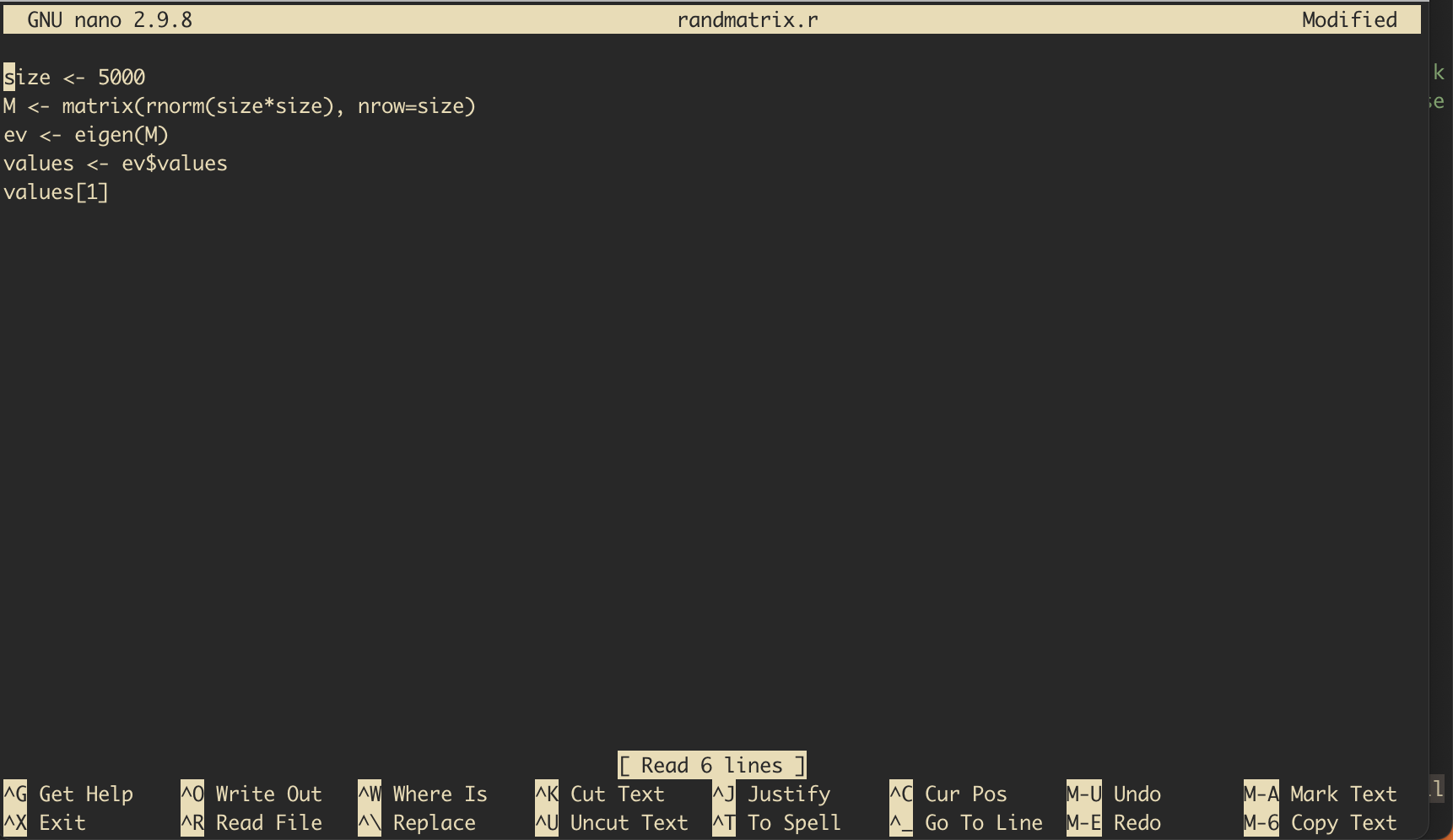
Fig. 21 Nano with the R script filled in#
To save it, press Ctrl+O, and hit enter. To exit the editor, press Ctrl+X. To make sure the text is saved properly, print it on screen using the cat command:
cat randmatrix.r
Now, let’s create the PBS script:
nano randmatrix.pbs
Inside the nano text editor, type this (or paste from the Web browser):
#!/bin/bash
#
#PBS -N random_matrix
#PBS -l select=1:ncpus=10:mem=10gb
#PBS -l walltime=0:20:00
#PBS -o random_matrix.txt
#PBS -j oe
cd $PBS_O_WORKDIR
module load r/4.1.3-gcc/9.5.0
Rscript randmatrix.r
Let’s go through the script, line by line. The first cryptic line says that it’s a script that is executed by the Linux shell. The next line is empty, followed by five lines that are the instructions to the scheduler (they start with #PBS):
-Nspecifies the name of the job;the first
-lline is the specification of resources: one node, ten CPUs, ten Gb of RAM, 1g interconnect;the second
-lline is the amount of walltime (twenty minutes);-ospecifies the name of the output file where the R output will be printed;-j oemeans “join output and error”, which is, if any errors happen, they will also be written intorandom_matrix.txt.
The rest are the instructions for bash. They are commands to execute once we get on the compute node that satisfies the request we provided in -l: go to the directory from which you have submitted qsub, load the R module, and execute the R script called randmatrix.r that we have created. Save the PBS script and exit nano (Ctrl+O, ENTER, Ctrl+X).
A very common question is how much walltime we should ask for. It’s a tricky question because there is no way of knowing how much time you will need until you actually try it. One rule of thumb is: make a rough guess, and ask for twice as much.
Now, let’s submit our batch job!
qsub randmatrix.pbs
We use the same command qsub that we have previously used for an interactive job, but now it’s much simpler, because all the hard work went into creating the PBS shell script randmatrix.pbs and qsub reads all the necessary information from there. If the submission was successful, it will give you the job ID, for example:
75696.pbs02
We can monitor the job’s progress with the qstat command. This is an example to list all jobs that are currently executed by you:
qstat -u <your Palmetto username>
You should see something like this:
pbs02:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
--------------- -------- -------- ---------- ------ --- --- ------ ----- - -----
75696.pbs02 dndawso c1_sing* random_ma* 26095* 1 10 10gb 00:20 R 00:00
You see the job ID, your Palmetto username, the name of the queue (more on that later), the name of the job (random_matrix), the resources requested (1 node, 10 CPUs, 10 gb of RAM, twenty minutes of walltime). The letter R means that the job is running (Q means “queued”, and F means “finished”), and then it shows for how long it’s been running (it basically just started).
Wait a little bit and do qstat again (you can hit the UP arrow to show the previous command). Elap time should now be a bit longer. The script should take a few minutes or so to execute. If you enter qstat -u <your Palmetto username> and the list is empty, then congratulations, we are done!
If everything went well, you should now see the file random_matrix.txt. Let’s print it on screen:
cat random_matrix.txt
[1] -69.78825+15.10709i
+------------------------------------------+
| PALMETTO CLUSTER PBS RESOURCES REQUESTED |
+------------------------------------------+
mem=10gb,walltime=00:20:00,ncpus=10
+-------------------------------------+
| PALMETTO CLUSTER PBS RESOURCES USED |
+-------------------------------------+
cput=00:03:18,mem=1025464kb,walltime=00:03:21,ncpus=10,cpupercent=65,vmem=1588316kb
Your output may be different since we used random matrices.
Another way to use qstat is to list the information about a particular job. Here, instead of -u, we use the -xf option, followed by the Job ID:
qstat -xf 75696.pbs02
This will give you a lot of information about the job, which is really useful for debugging. If you have a problem and you need our help, it is very helpful to us if you provide the job ID so we can do qstat -xf on it and get the job details.
How many jobs can you run at the same time? It depends on how much resources you ask for. If each job asks for a small amount of resources, you can do a large amount of jobs simultaneously. If each job needs a large amount of resources, only a few of them can be running simultaneously, and the rest of them will be waiting in the queue until the jobs that are running are completed. This is a way to ensure that Palmetto is used fairly.
These limits of the number of simultaneous jobs is not carved in stone, but it changes depending on how much Palmetto is used at the moment. To see the current queue configuration, you can execute this command (note that it only works on the login node):
checkqueuecfg
You will see something like this:
1G QUEUES min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
c1_solo 1 1 5000gb 500 336:00:00
c1_single 2 24 60000gb 500 336:00:00
c1_tiny 25 128 51200gb 50 336:00:00
c1_small 129 512 61440gb 15 336:00:00
c1_medium 513 2048 16384gb 1 336:00:00
c1_large 2049 4096 32768gb 1 336:00:00
IB QUEUES min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
c2_single 1 56 10000gb 25 72:00:00
c2_tiny 57 200 32000gb 10 72:00:00
c2_small 201 512 21504gb 3 72:00:00
c2_medium 513 2048 32768gb 2 72:00:00
c2_large 2049 4096 32768gb 1 72:00:00
c2_fdr_single 1 56 40000gb 100 72:00:00
c2_fdr_tiny 57 200 80000gb 25 72:00:00
c2_fdr_small 201 512 35840gb 5 72:00:00
c2_fdr_medium 513 2048 81920gb 5 72:00:00
c2_fdr_large 2049 4096 32768gb 1 72:00:00
c2_hdr_single 1 56 24000gb 20 72:00:00
c2_hdr_tiny 57 200 80000gb 25 72:00:00
c2_hdr_small 201 512 14336gb 2 72:00:00
c2_hdr_medium 513 2048 32768gb 2 72:00:00
c2_hdr_large 2049 4096 65536gb 2 72:00:00
GPU QUEUES min_gpus_per_job max_gpus_per_job min_cores_per_job max_cores_per_job max_mem_per_queue max_jobs_per_queue max_walltime
gpu_dgxa100_e 1 8 1 256 1000gb 1 72:00:00
gpu_dgx1_e 1 8 1 80 500gb 1 72:00:00
gpu_small_a100 1 4 1 96 4800gb 10 72:00:00
gpu_medium_a100 5 9 1 256 5120gb 2 72:00:00
gpu_large_a100 10 256 1 2048 10240gb 1 72:00:00
gpu_small_v100 1 4 1 96 19200gb 20 72:00:00
gpu_medium_v100 5 9 1 256 12800gb 5 72:00:00
gpu_large_v100 10 256 1 2048 20480gb 2 72:00:00
gpu_small_p100 1 4 1 96 5760gb 12 72:00:00
gpu_medium_p100 5 9 1 256 5120gb 2 72:00:00
gpu_large_p100 10 256 1 2048 30720gb 3 72:00:00
gpu_small_k240 1 4 1 96 12000gb 25 72:00:00
gpu_medium_k240 5 9 1 256 25600gb 10 72:00:00
gpu_large_k240 10 256 1 2048 102400gb 10 72:00:00
SMP QUEUE min_cores max_cores max_jobs max_walltime
bigmem 1 80 3 168:00:00
SKYLIGHT QUEUES max_jobs max_walltime
skystd_e 100 240:00:00
skylm_e 20 240:00:00
skygpu_e 50 240:00:00
'max_mem' is the maximum amount of memory all your jobs in this queue can
consume at any one time. For example, if the max_mem for the solo queue
is 4000gb, and your solo jobs each need 10gb, then you can run a
maximum number of 4000/10 = 400 jobs in the solo queue, even though the
current max_jobs setting for the solo queue may be set higher than 400.
NOTE: Although you may be within the limits for a queue, there may not
be any resources of the type you are requesting currently available.
NOTE: An array job cannot have more indexes than the
current max_jobs value otherwise the job will not start.
One thing to note is that 1g nodes have maximum walltime of 336 hours (two weeks), and InfiniBand (hdr and fdr) nodes have maximum walltime of 72 hours (three days). Since the GPUs are only installed on the InfiniBand nodes, any job that asks for a GPU will also be subject to 72-hour limit. The maximum number of simultaneous jobs really depends on how much CPUs and memory you are asking; for example, for 1 node, 10 CPUs and 10 Gb of RAM (what we asked for in our randmatrix job), we can run 500 jobs on 1g nodes (queue name c1_single), but only 25 jobs on InfiniBand nodes (queue name c2_single). This number changes day to day, depending on how busy the cluster is –on busy days, this number is lowered so more people have a chance to run their jobs on Palmetto.
Key Points
Batch jobs don’t require interaction with the user and run on the compute nodes on the background.
To submit a batch job, users need to provide a PBS script which is passed to the scheduler.
Jobs are assigned to queues, according to the amount of requested resources.
Different queues have different limits on the walltime and the number of parallel jobs.
qstatallows you to check the status of your jobs.